 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Calibration of Win Rate Estimation with LLM Evaluators
Paper and Code

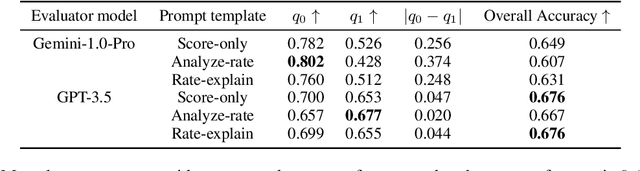
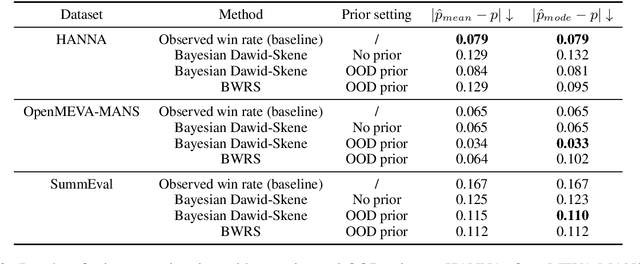

Recent advances in large language models (LLMs) show the potential of using LLMs as evaluators for assessing the quality of text generations from LLMs. However, applying LLM evaluators naively to compare or judge between different systems can lead to unreliable results due to the intrinsic win rate estimation bias of LLM evaluators. In order to mitigate this problem, we propose two calibration methods, Bayesian Win Rate Sampling (BWRS) and Bayesian Dawid-Skene, both of which leverage Bayesian inference to more accurately infer the true win rate of generative language models. We empirically validate our methods on six datasets covering story generation, summarization, and instruction following tasks. We show that both our methods are effective in improving the accuracy of win rate estimation using LLMs as evaluators, offering a promising direction for reliable automatic text quality evaluation.