 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesFormer: Transformer with Uncertainty Estimation
Paper and Code
Jun 02, 2022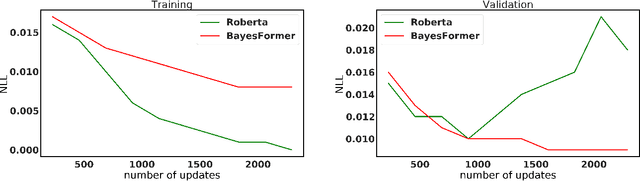
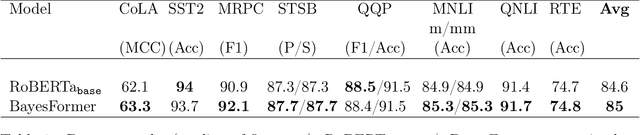
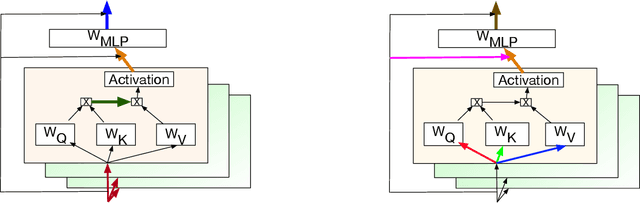

Transformer has become ubiquitous due to its dominant performance in various NLP and image processing tasks. However, it lacks understanding of how to generate mathematically grounded uncertainty estimates for transformer architectures. Models equipped with such uncertainty estimates can typically improve predictive performance, make networks robust, avoid over-fitting and used as acquisition function in active learning. In this paper, we introduce BayesFormer, a Transformer model with dropouts designed by Bayesian theory. We proposed a new theoretical framework to extend the approximate variational inference-based dropout to Transformer-based architectures. Through extensive experiments, we validate the proposed architecture in four paradigms and show improvements across the board: language modeling and classification, long-sequence understanding, machine translation and acquisition function for active learning.