 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBAN-ABSA: An Aspect-Based Sentiment Analysis dataset for Bengali and it's baseline evaluation
Paper and Code
Dec 01, 2020
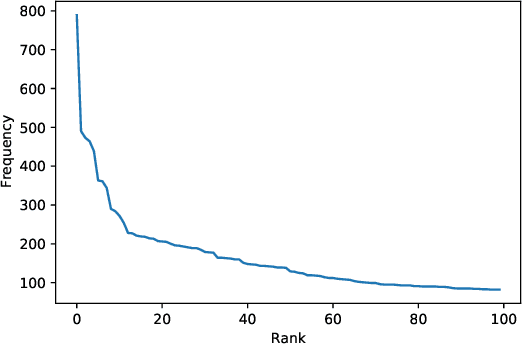
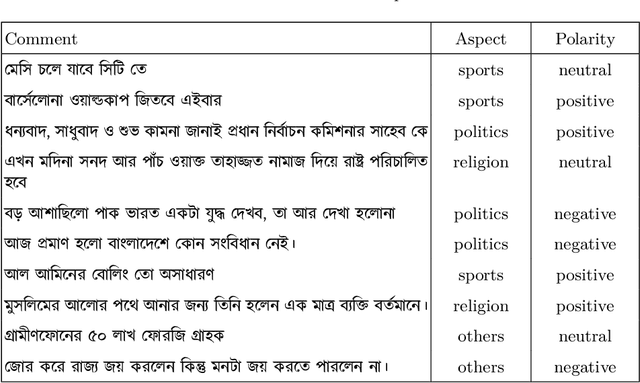
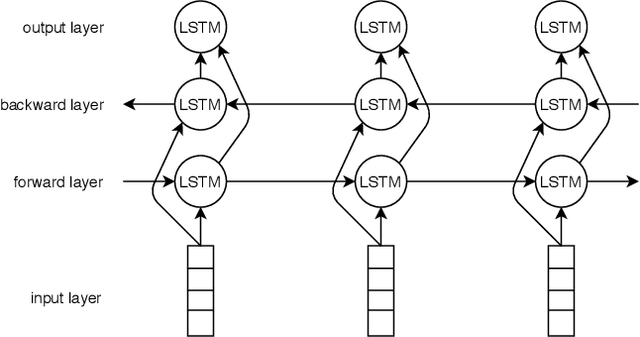
Due to the breathtaking growth of social media or newspaper user comments, online product reviews comments, sentiment analysis (SA) has captured substantial interest from the researchers. With the fast increase of domain, SA work aims not only to predict the sentiment of a sentence or document but also to give the necessary detail on different aspects of the sentence or document (i.e. aspect-based sentiment analysis). A considerable number of datasets for SA and aspect-based sentiment analysis (ABSA) have been made available for English and other well-known European languages. In this paper, we present a manually annotated Bengali dataset of high quality, BAN-ABSA, which is annotated with aspect and its associated sentiment by 3 native Bengali speakers. The dataset consists of 2,619 positive, 4,721 negative and 1,669 neutral data samples from 9,009 unique comments gathered from some famous Bengali news portals. In addition, we conducted a baseline evaluation with a focus on deep learning model, achieved an accuracy of 78.75% for aspect term extraction and accuracy of 71.08% for sentiment classification. Experiments on the BAN-ABSA dataset show that the CNN model is better in terms of accuracy though Bi-LSTM significantly outperforms CNN model in terms of average F1-score.