 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBaird Counterexample is Solved: with an example of How to Debug a Two-time-scale Algorithm
Paper and Code
Sep 02, 2023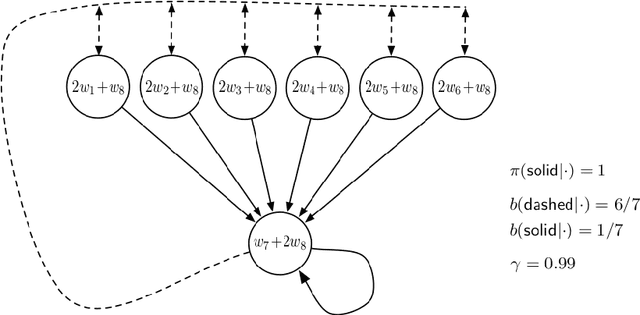
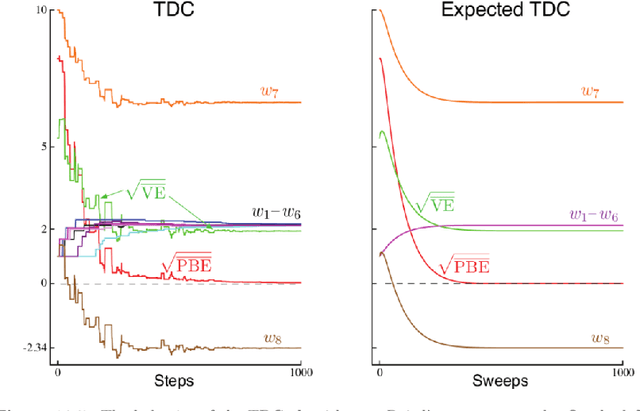
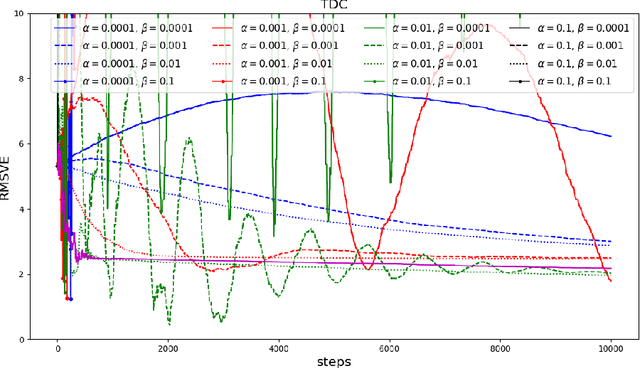
Baird counterexample was proposed by Leemon Baird in 1995, first used to show that the Temporal Difference (TD(0)) algorithm diverges on this example. Since then, it is often used to test and compare off-policy learning algorithms. Gradient TD algorithms solved the divergence issue of TD on Baird counterexample. However, their convergence on this example is still very slow, and the nature of the slowness is not well understood, e.g., see (Sutton and Barto 2018). This note is to understand in particular, why TDC is slow on this example, and provide a debugging analysis to understand this behavior. Our debugging technique can be used to study the convergence behavior of two-time-scale stochastic approximation algorithms. We also provide empirical results of the recent Impression GTD algorithm on this example, showing the convergence is very fast, in fact, in a linear rate. We conclude that Baird counterexample is solved, by an algorithm with the convergence guarantee to the TD solution in general, and a fast convergence rate.