Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBAE: BERT-based Adversarial Examples for Text Classification
Paper and Code

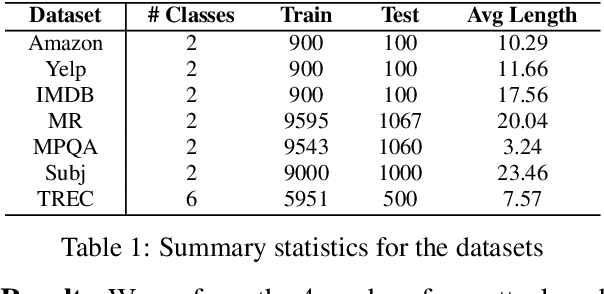
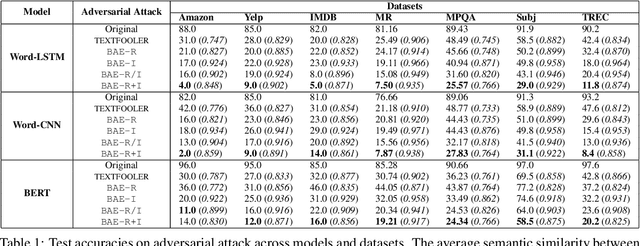
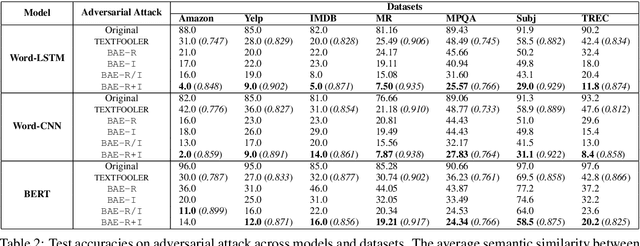
Modern text classification models are susceptible to adversarial examples, perturbed versions of the original text indiscernible by humans but which get misclassified by the model. We present BAE, a powerful black box attack for generating grammatically correct and semantically coherent adversarial examples. BAE replaces and inserts tokens in the original text by masking a portion of the text and leveraging a language model to generate alternatives for the masked tokens. Compared to prior work, we show that BAE performs a stronger attack on three widely used models for seven text classification datasets.
View paper on