 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBackdoor Attack is A Devil in Federated GAN-based Medical Image Synthesis
Paper and Code
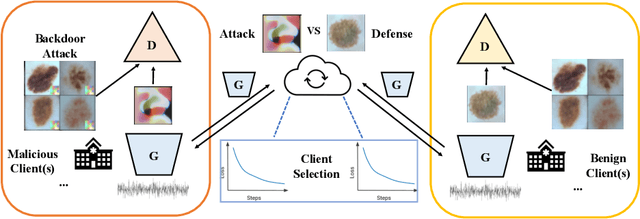



Deep Learning-based image synthesis techniques have been applied in healthcare research for generating medical images to support open research. Training generative adversarial neural networks (GAN) usually requires large amounts of training data. Federated learning (FL) provides a way of training a central model using distributed data from different medical institutions while keeping raw data locally. However, FL is vulnerable to backdoor attack, an adversarial by poisoning training data, given the central server cannot access the original data directly. Most backdoor attack strategies focus on classification models and centralized domains. In this study, we propose a way of attacking federated GAN (FedGAN) by treating the discriminator with a commonly used data poisoning strategy in backdoor attack classification models. We demonstrate that adding a small trigger with size less than 0.5 percent of the original image size can corrupt the FL-GAN model. Based on the proposed attack, we provide two effective defense strategies: global malicious detection and local training regularization. We show that combining the two defense strategies yields a robust medical image generation.