 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBack to Event Basics: Self-Supervised Learning of Image Reconstruction for Event Cameras via Photometric Constancy
Paper and Code
Sep 17, 2020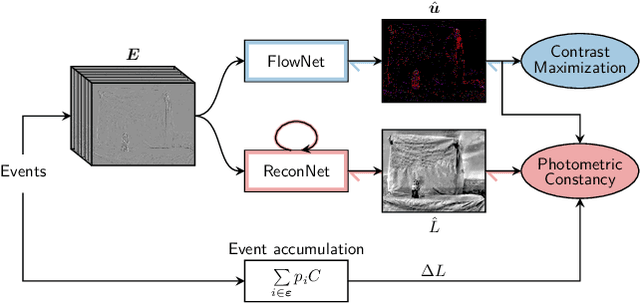

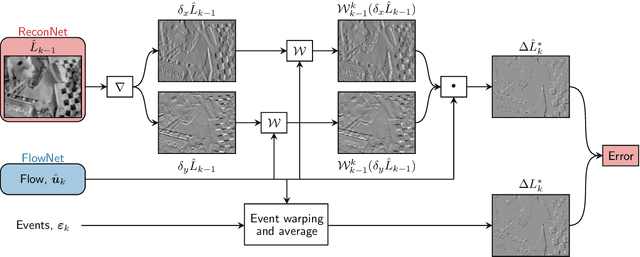
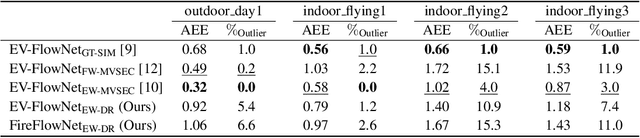
Event cameras are novel vision sensors that sample, in an asynchronous fashion, brightness increments with low latency and high temporal resolution. The resulting streams of events are of high value by themselves, especially for high speed motion estimation. However, a growing body of work has also focused on the reconstruction of intensity frames from the events, as this allows bridging the gap with the existing literature on appearance- and frame-based computer vision. Recent work has mostly approached this intensity reconstruction problem using neural networks trained with synthetic, ground-truth data. Nevertheless, since accurate ground truth is only available in simulation, these methods are subject to the reality gap and, to ensure generalizability, their training datasets need to be carefully designed. In this work, we approach, for the first time, the reconstruction problem from a self-supervised learning perspective. Our framework combines estimated optical flow and the event-based photometric constancy to train neural networks without the need for any ground-truth or synthetic data. Results across multiple datasets show that the performance of the proposed approach is in line with the state-of-the-art.