 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuxiliary Multimodal LSTM for Audio-visual Speech Recognition and Lipreading
Paper and Code
Mar 17, 2017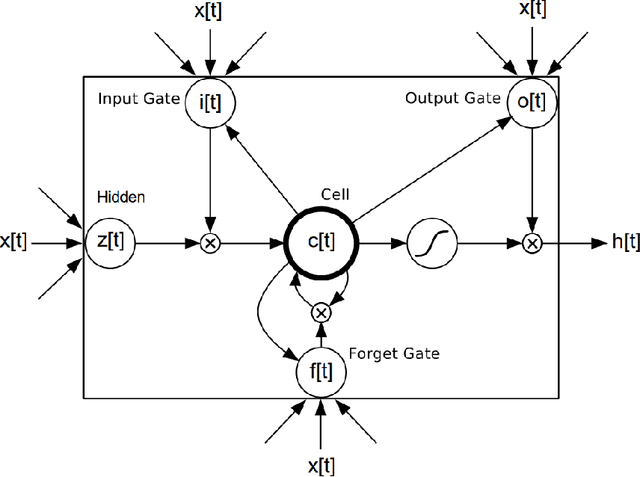

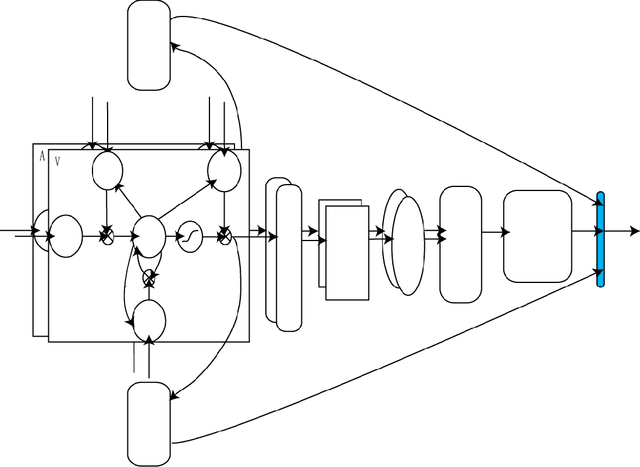

The Aduio-visual Speech Recognition (AVSR) which employs both the video and audio information to do Automatic Speech Recognition (ASR) is one of the application of multimodal leaning making ASR system more robust and accuracy. The traditional models usually treated AVSR as inference or projection but strict prior limits its ability. As the revival of deep learning, Deep Neural Networks (DNN) becomes an important toolkit in many traditional classification tasks including ASR, image classification, natural language processing. Some DNN models were used in AVSR like Multimodal Deep Autoencoders (MDAEs), Multimodal Deep Belief Network (MDBN) and Multimodal Deep Boltzmann Machine (MDBM) that actually work better than traditional methods. However, such DNN models have several shortcomings: (1) They don't balance the modal fusion and temporal fusion, or even haven't temporal fusion; (2)The architecture of these models isn't end-to-end, the training and testing getting cumbersome. We propose a DNN model, Auxiliary Multimodal LSTM (am-LSTM), to overcome such weakness. The am-LSTM could be trained and tested once, moreover easy to train and preventing overfitting automatically. The extensibility and flexibility are also take into consideration. The experiments show that am-LSTM is much better than traditional methods and other DNN models in three datasets.