 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoScale: Optimizing Energy Efficiency of End-to-End Edge Inference under Stochastic Variance
Paper and Code
May 06, 2020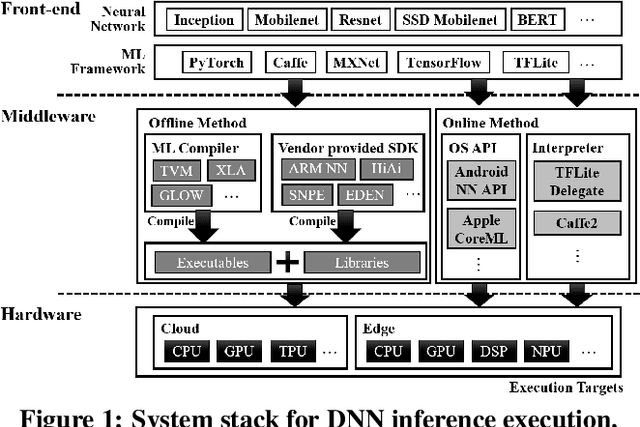

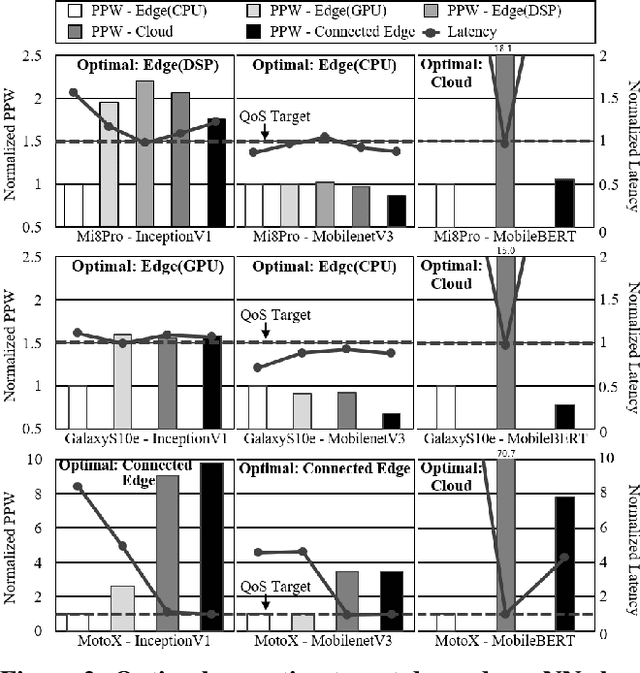

Deep learning inference is increasingly run at the edge. As the programming and system stack support becomes mature, it enables acceleration opportunities within a mobile system, where the system performance envelope is scaled up with a plethora of programmable co-processors. Thus, intelligent services designed for mobile users can choose between running inference on the CPU or any of the co-processors on the mobile system, or exploiting connected systems, such as the cloud or a nearby, locally connected system. By doing so, the services can scale out the performance and increase the energy efficiency of edge mobile systems. This gives rise to a new challenge - deciding when inference should run where. Such execution scaling decision becomes more complicated with the stochastic nature of mobile-cloud execution, where signal strength variations of the wireless networks and resource interference can significantly affect real-time inference performance and system energy efficiency. To enable accurate, energy-efficient deep learning inference at the edge, this paper proposes AutoScale. AutoScale is an adaptive and light-weight execution scaling engine built upon the custom-designed reinforcement learning algorithm. It continuously learns and selects the most energy-efficient inference execution target by taking into account characteristics of neural networks and available systems in the collaborative cloud-edge execution environment while adapting to the stochastic runtime variance. Real system implementation and evaluation, considering realistic execution scenarios, demonstrate an average of 9.8 and 1.6 times energy efficiency improvement for DNN edge inference over the baseline mobile CPU and cloud offloading, while meeting the real-time performance and accuracy requirement.