 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating the Correctness Assessment of AI-generated Code for Security Contexts
Paper and Code
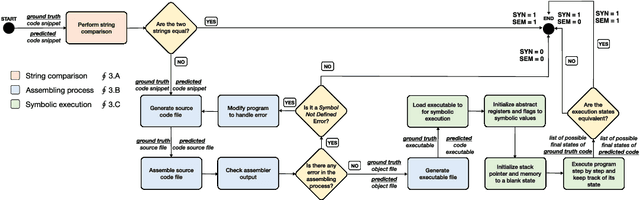

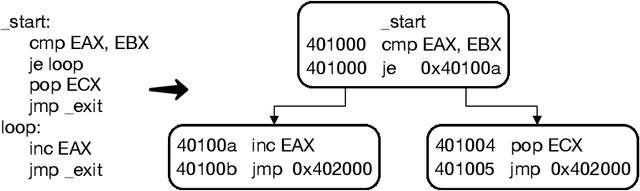
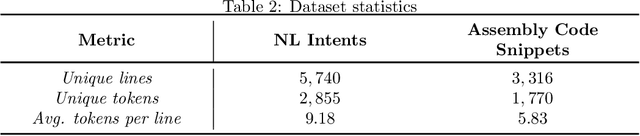
In this paper, we propose a fully automated method, named ACCA, to evaluate the correctness of AI-generated code for security purposes. The method uses symbolic execution to assess whether the AI-generated code behaves as a reference implementation. We use ACCA to assess four state-of-the-art models trained to generate security-oriented assembly code and compare the results of the evaluation with different baseline solutions, including output similarity metrics, widely used in the field, and the well-known ChatGPT, the AI-powered language model developed by OpenAI. Our experiments show that our method outperforms the baseline solutions and assesses the correctness of the AI-generated code similar to the human-based evaluation, which is considered the ground truth for the assessment in the field. Moreover, ACCA has a very strong correlation with human evaluation (Pearson's correlation coefficient r=0.84 on average). Finally, since it is a fully automated solution that does not require any human intervention, the proposed method performs the assessment of every code snippet in ~0.17s on average, which is definitely lower than the average time required by human analysts to manually inspect the code, based on our experience.