 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic sleep stage classification with deep residual networks in a mixed-cohort setting
Paper and Code
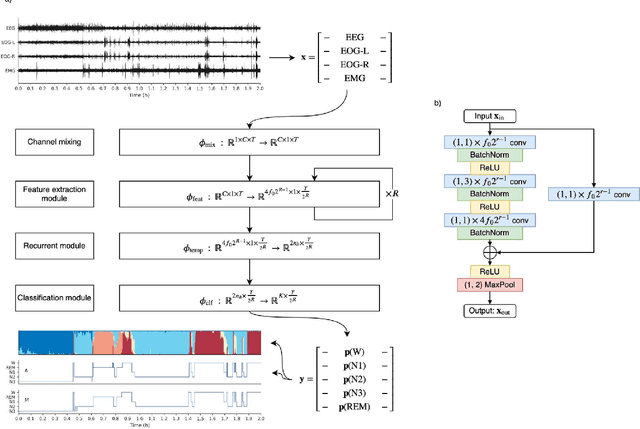
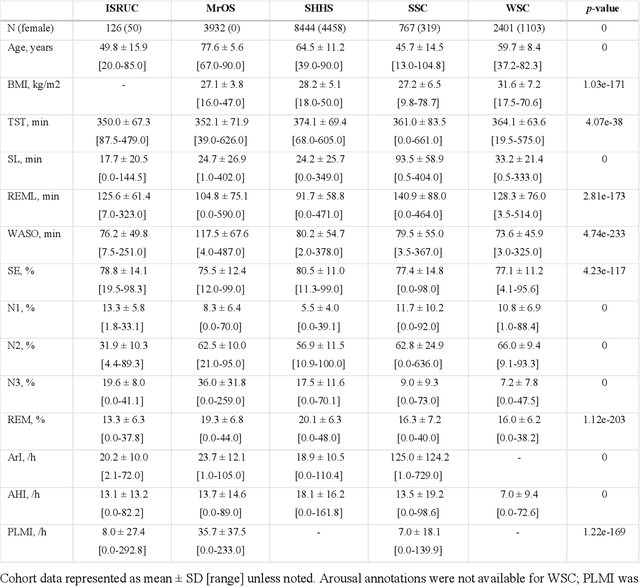
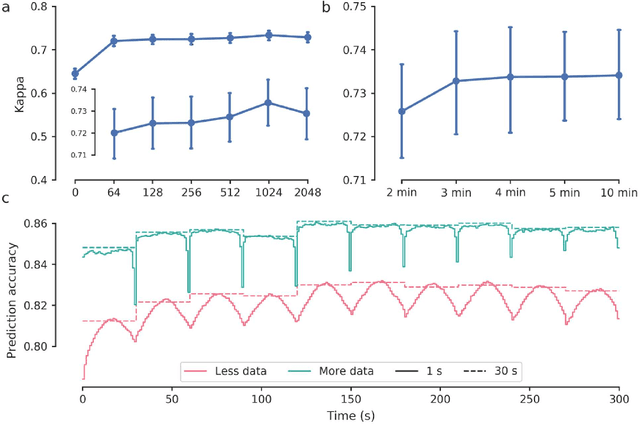
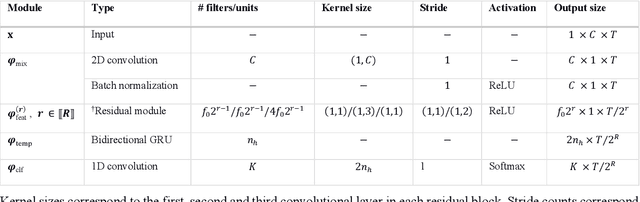
Study Objectives: Sleep stage scoring is performed manually by sleep experts and is prone to subjective interpretation of scoring rules with low intra- and interscorer reliability. Many automatic systems rely on few small-scale databases for developing models, and generalizability to new datasets is thus unknown. We investigated a novel deep neural network to assess the generalizability of several large-scale cohorts. Methods: A deep neural network model was developed using 15684 polysomnography studies from five different cohorts. We applied four different scenarios: 1) impact of varying time-scales in the model; 2) performance of a single cohort on other cohorts of smaller, greater or equal size relative to the performance of other cohorts on a single cohort; 3) varying the fraction of mixed-cohort training data compared to using single-origin data; and 4) comparing models trained on combinations of data from 2, 3, and 4 cohorts. Results: Overall classification accuracy improved with increasing fractions of training data (0.25$\%$: 0.782 $\pm$ 0.097, 95$\%$ CI [0.777-0.787]; 100$\%$: 0.869 $\pm$ 0.064, 95$\%$ CI [0.864-0.872]), and with increasing number of data sources (2: 0.788 $\pm$ 0.102, 95$\%$ CI [0.787-0.790]; 3: 0.808 $\pm$ 0.092, 95$\%$ CI [0.807-0.810]; 4: 0.821 $\pm$ 0.085, 95$\%$ CI [0.819-0.823]). Different cohorts show varying levels of generalization to other cohorts. Conclusions: Automatic sleep stage scoring systems based on deep learning algorithms should consider as much data as possible from as many sources available to ensure proper generalization. Public datasets for benchmarking should be made available for future research.