 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic lung segmentation in routine imaging is a data diversity problem, not a methodology problem
Paper and Code


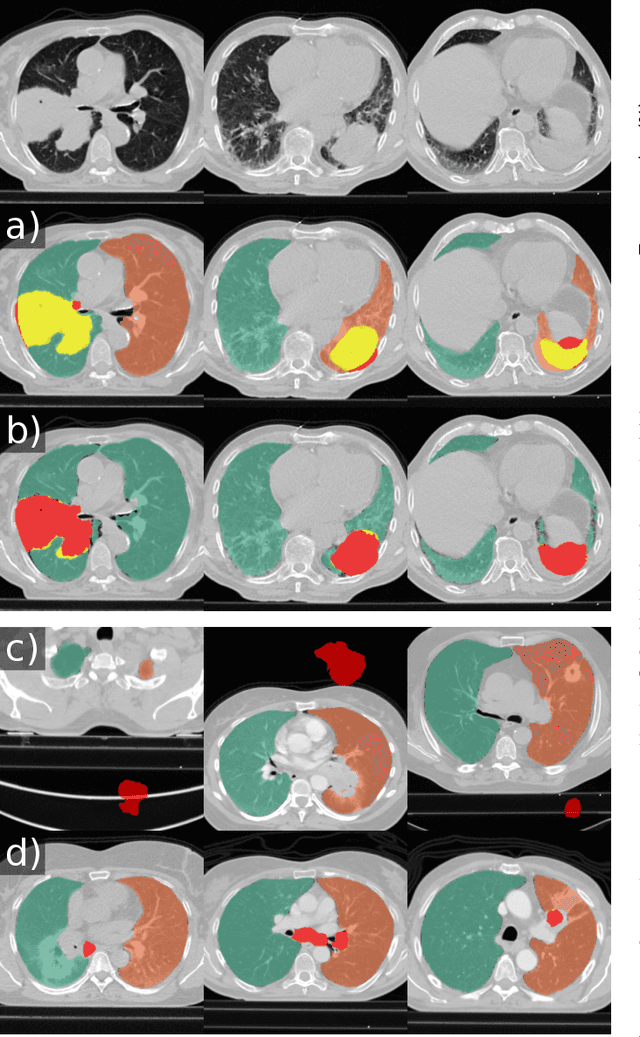
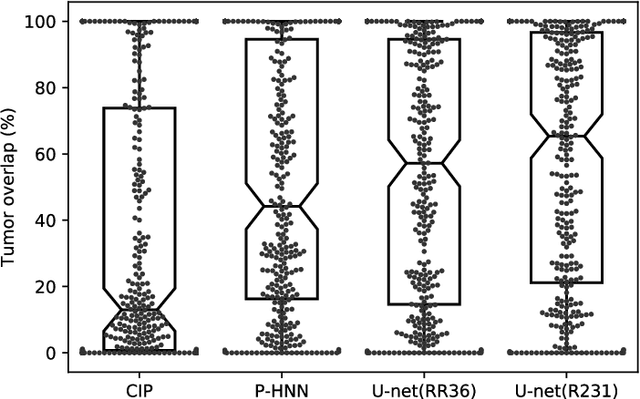
Automated segmentation of anatomical structures is a crucial step in many medical image analysis tasks. For lung segmentation, a variety of approaches exist, involving sophisticated pipelines trained and validated on a range of different data sets. However, during translation to clinical routine the applicability of these approaches across diseases remains limited. Here, we show that the accuracy and reliability of lung segmentation algorithms on demanding cases primarily does not depend on methodology, but on the diversity of training data. We compare 4 generic deep learning approaches and 2 published lung segmentation algorithms on routine imaging data with more than 6 different disease patterns and 3 published data sets. We show that a basic approach - U-net - performs either better, or competitively with other approaches on both routine data and published data sets, and outperforms published approaches once trained on a diverse data set covering multiple diseases. Training data composition consistently has a bigger impact than algorithm choice on accuracy across test data sets. We carefully analyse the impact of data diversity, and the specifications of annotations on both training and validation sets to provide a reference for algorithms, training data, and annotation. Results on a seemingly well understood task of lung segmentation suggest the critical importance of training data diversity compared to model choice.