Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Extraction of Subcategorization Frames for Czech
Paper and Code
Sep 08, 2000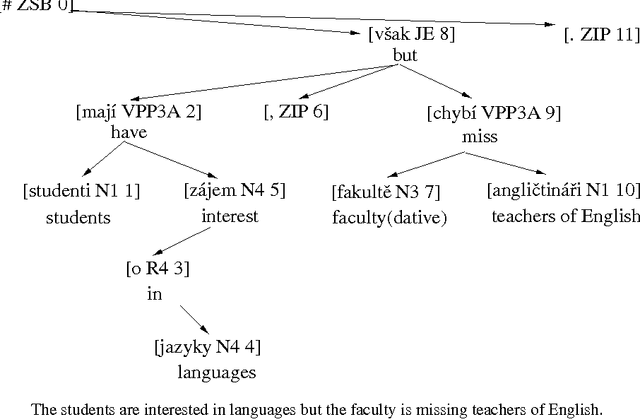
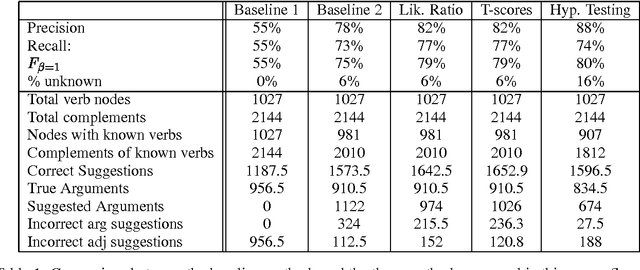
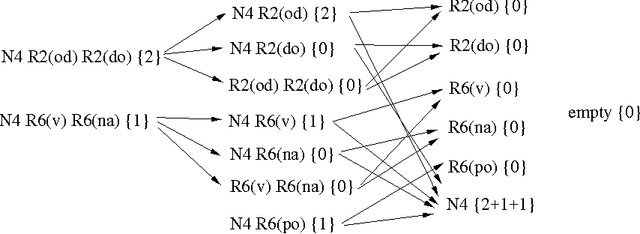
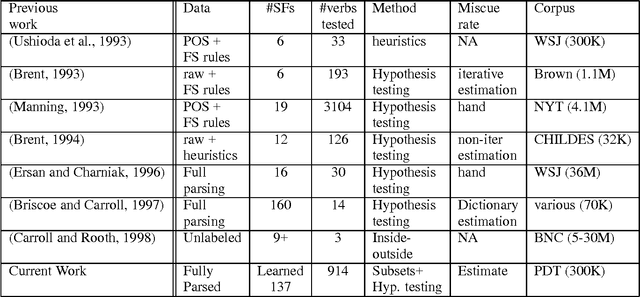
We present some novel machine learning techniques for the identification of subcategorization information for verbs in Czech. We compare three different statistical techniques applied to this problem. We show how the learning algorithm can be used to discover previously unknown subcategorization frames from the Czech Prague Dependency Treebank. The algorithm can then be used to label dependents of a verb in the Czech treebank as either arguments or adjuncts. Using our techniques, we ar able to achieve 88% precision on unseen parsed text.
* Proceedings of the 18th International Conference on Computational
Linguistics (Coling 2000), Universit * 7 pages. Another version under the name "Learning Verb
Subcategorization from Corpora: Counting Frame Subsets", authors: Zeman,
Sarkar, in proceedings of LREC 2000, Athens, Greece
View paper on