 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Dataset Augmentation Using Virtual Human Simulation
Paper and Code
May 01, 2019
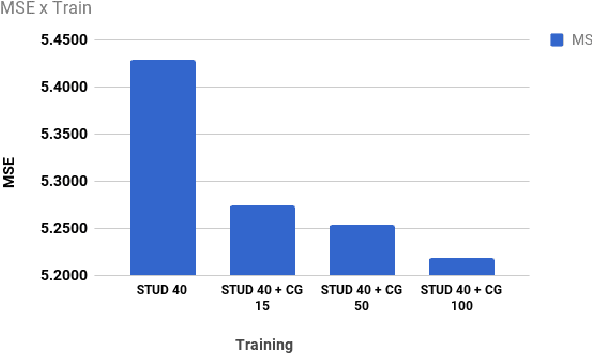


Virtual Human Simulation has been widely used for different purposes, such as comfort or accessibility analysis. In this paper, we investigate the possibility of using this type of technique to extend the training datasets of pedestrians to be used with machine learning techniques. Our main goal is to verify if Computer Graphics (CG) images of virtual humans with a simplistic rendering can be efficient in order to augment datasets used for training machine learning methods. In fact, from a machine learning point of view, there is a need to collect and label large datasets for ground truth, which sometimes demands manual annotation. In addition, find out images and videos with real people and also provide ground truth of people detection and counting is not trivial. If CG images, which can have a ground truth automatically generated, can also be used as training in machine learning techniques for pedestrian detection and counting, it can certainly facilitate and optimize the whole process of event detection. In particular, we propose to parametrize virtual humans using a data-driven approach. Results demonstrated that using the extended datasets with CG images outperforms the results when compared to only real images sequences.