 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Cross-Replica Sharding of Weight Update in Data-Parallel Training
Paper and Code
Apr 28, 2020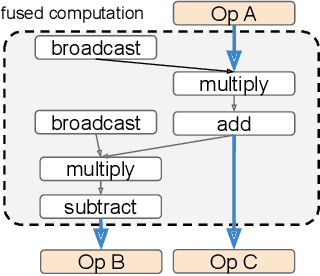
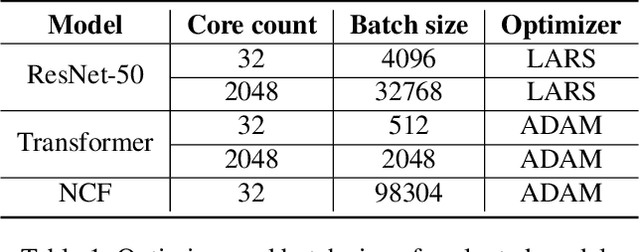
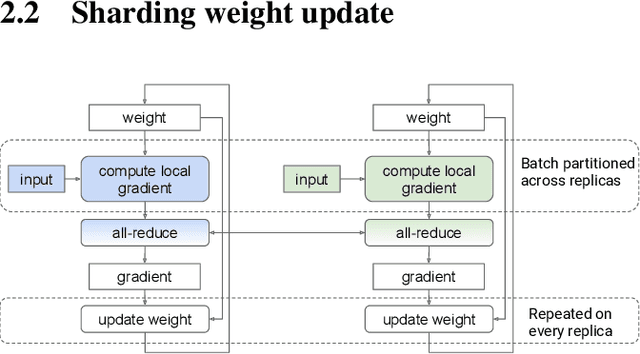
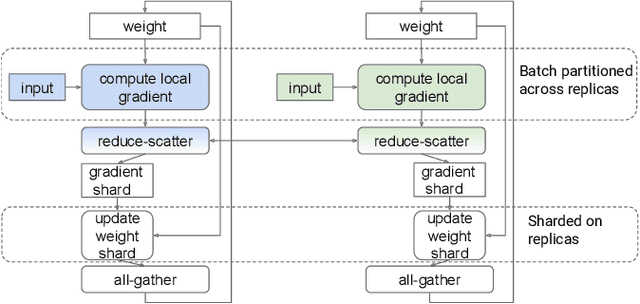
In data-parallel synchronous training of deep neural networks, different devices (replicas) run the same program with different partitions of the training batch, but weight update computation is repeated on all replicas, because the weights do not have a batch dimension to partition. This can be a bottleneck for performance and scalability in typical language models with large weights, and models with small per-replica batch size which is typical in large-scale training. This paper presents an approach to automatically shard the weight update computation across replicas with efficient communication primitives and data formatting, using static analysis and transformations on the training computation graph. We show this technique achieves substantial speedups on typical image and language models on Cloud TPUs, requiring no change to model code. This technique helps close the gap between traditionally expensive (ADAM) and cheap (SGD) optimizers, as they will only take a small part of training step time and have similar peak memory usage. It helped us to achieve state-of-the-art training performance in Google's MLPerf 0.6 submission.