 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Tone Transcription and Clustering with Tone2Vec
Paper and Code
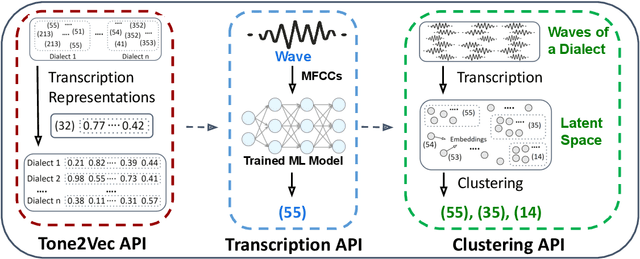

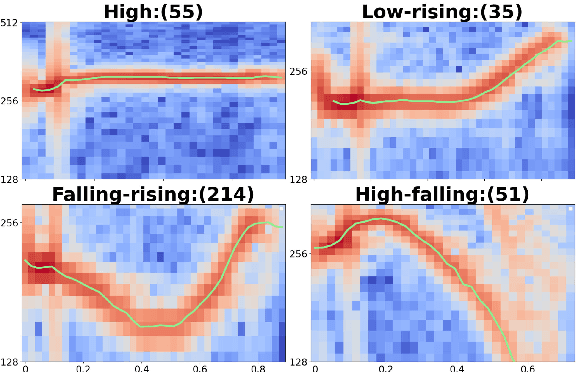

Lexical tones play a crucial role in Sino-Tibetan languages. However, current phonetic fieldwork relies on manual effort, resulting in substantial time and financial costs. This is especially challenging for the numerous endangered languages that are rapidly disappearing, often compounded by limited funding. In this paper, we introduce pitch-based similarity representations for tone transcription, named Tone2Vec. Experiments on dialect clustering and variance show that Tone2Vec effectively captures fine-grained tone variation. Utilizing Tone2Vec, we develop the first automatic approach for tone transcription and clustering by presenting a novel representation transformation for transcriptions. Additionally, these algorithms are systematically integrated into an open-sourced and easy-to-use package, ToneLab, which facilitates automated fieldwork and cross-regional, cross-lexical analysis for tonal languages. Extensive experiments were conducted to demonstrate the effectiveness of our methods.