 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Identification of Toxic Code Reviews: How Far Can We Go?
Paper and Code
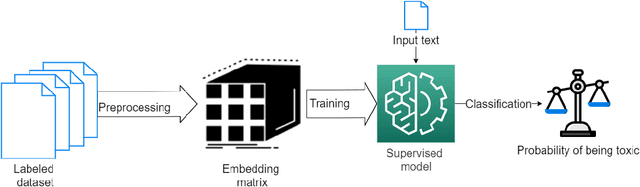
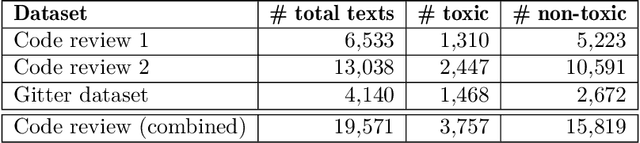
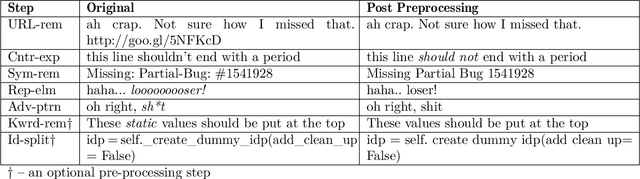
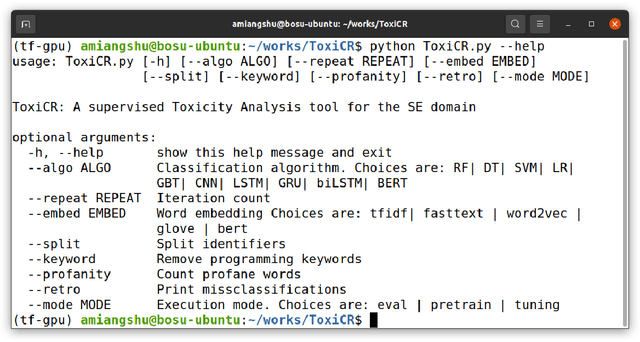
Toxic conversations during software development interactions may have serious repercussions on a Free and Open Source Software (FOSS) development project. For example, victims of toxic conversations may become afraid to express themselves, therefore get demotivated, and may eventually leave the project. Automated filtering of toxic conversations may help a FOSS community to maintain healthy interactions among its members. However, off-the-shelf toxicity detectors perform poorly on Software Engineering (SE) dataset, such as one curated from code review comments. To encounter this challenge, we present ToxiCR, a supervised learning-based toxicity identification tool for code review interactions. ToxiCR includes a choice to select one of the ten supervised learning algorithms, an option to select text vectorization techniques, five mandatory and three optional SE domain specific processing steps, and a large scale labeled dataset of 19,571 code review comments. With our rigorous evaluation of the models with various combinations of preprocessing steps and vectorization techniques, we have identified the best combination for our dataset that boosts 95.8% accuracy and 88.9% F1 score. ToxiCR significantly outperforms existing toxicity detectors on our dataset. We have released our dataset, pretrained models, evaluation results, and source code publicly available at: https://github.com/WSU-SEAL/ToxiCR.