 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoEnsemble: Automated Ensemble Search Framework for Semantic Segmentation Using Image Labels
Paper and Code


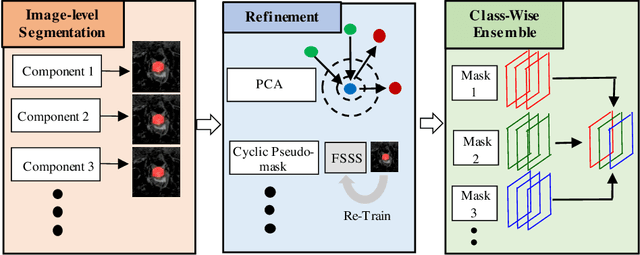

A key bottleneck of employing state-of-the-art semantic segmentation networks in the real world is the availability of training labels. Standard semantic segmentation networks require massive pixel-wise annotated labels to reach state-of-the-art prediction quality. Hence, several works focus on semantic segmentation networks trained with only image-level annotations. However, when scrutinizing the state-of-the-art results in more detail, we notice that although they are very close to each other on average prediction quality, different approaches perform better in different classes while providing low quality in others. To address this problem, we propose a novel framework, AutoEnsemble, which employs an ensemble of the "pseudo-labels" for a given set of different segmentation techniques on a class-wise level. Pseudo-labels are the pixel-wise predictions of the image-level semantic segmentation frameworks used to train the final segmentation model. Our pseudo-labels seamlessly combine the strong points of multiple segmentation techniques approaches to reach superior prediction quality. We reach up to 2.4% improvement over AutoEnsemble's components. An exhaustive analysis was performed to demonstrate AutoEnsemble's effectiveness over state-of-the-art frameworks for image-level semantic segmentation.