 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmenting Novelty Search with a Surrogate Model to Engineer Meta-Diversity in Ensembles of Classifiers
Paper and Code
Feb 08, 2022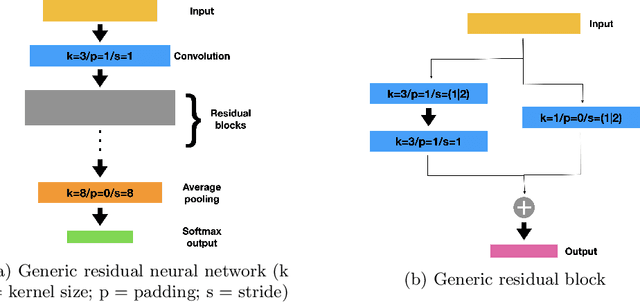
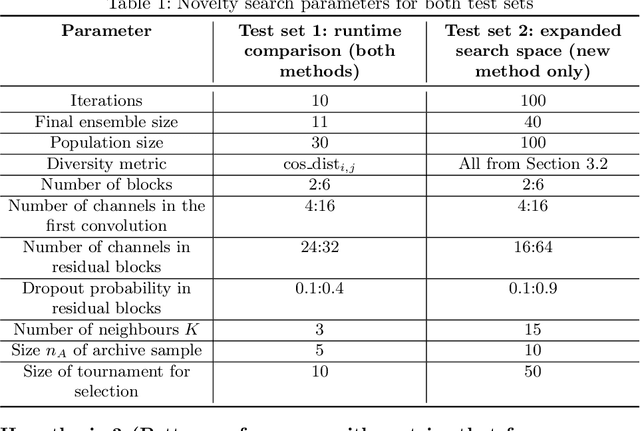

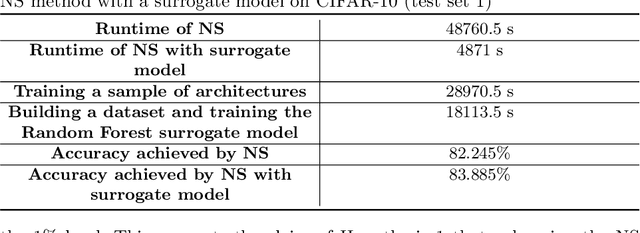
Using Neuroevolution combined with Novelty Search to promote behavioural diversity is capable of constructing high-performing ensembles for classification. However, using gradient descent to train evolved architectures during the search can be computationally prohibitive. Here we propose a method to overcome this limitation by using a surrogate model which estimates the behavioural distance between two neural network architectures required to calculate the sparseness term in Novelty Search. We demonstrate a speedup of 10 times over previous work and significantly improve on previous reported results on three benchmark datasets from Computer Vision -- CIFAR-10, CIFAR-100, and SVHN. This results from the expanded architecture search space facilitated by using a surrogate. Our method represents an improved paradigm for implementing horizontal scaling of learning algorithms by making an explicit search for diversity considerably more tractable for the same bounded resources.