 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmentation Policy Generation for Image Classification Using Large Language Models
Paper and Code
Oct 17, 2024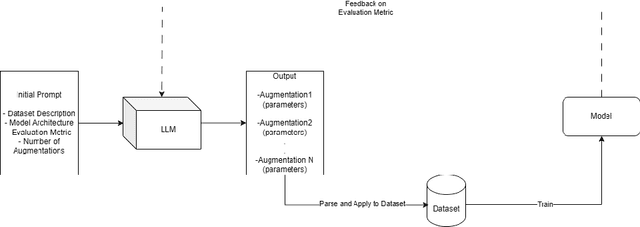
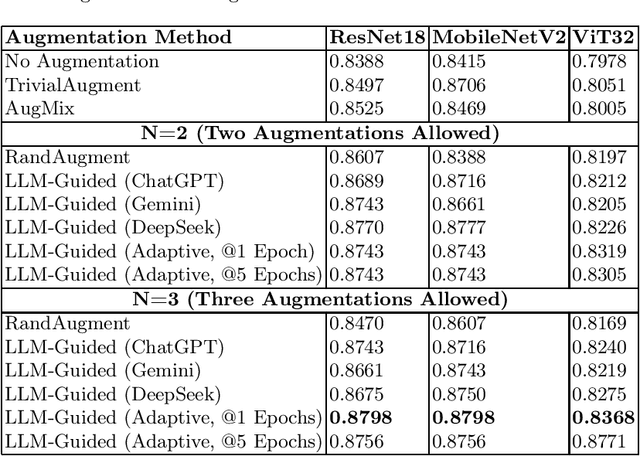
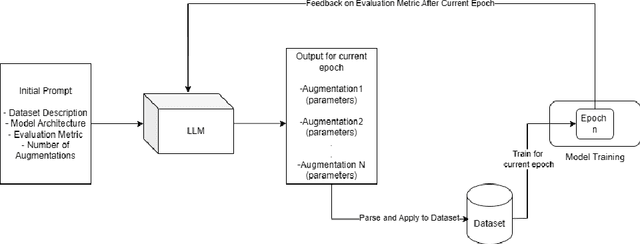
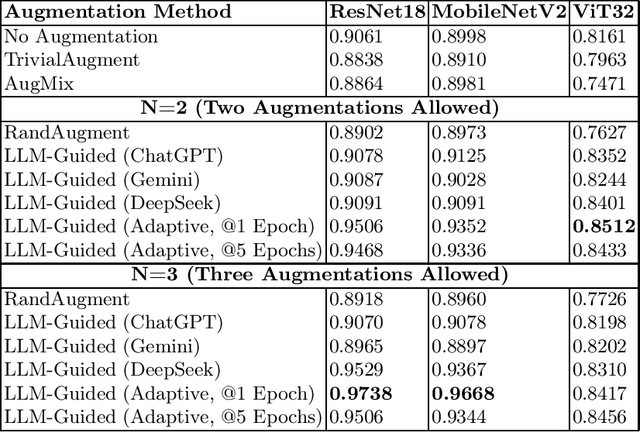
Automated data augmentation methods have significantly improved the performance and generalization capability of deep learning models in image classification. Yet, most state-of-the-art methods are optimized on common benchmark datasets, limiting their applicability to more diverse or domain-specific data, such as medical datasets. In this paper, we propose a strategy that uses large language models to automatically generate efficient augmentation policies, customized to fit the specific characteristics of any dataset and model architecture. The proposed method iteratively interacts with an LLM to obtain and refine the augmentation policies on model performance feedback, creating a dataset-agnostic data augmentation pipeline. The proposed method was evaluated on medical imaging datasets, showing a clear improvement over state-of-the-art methods. The proposed approach offers an adaptive and scalable solution. Although it increases computational cost, it significantly boosts model robustness, automates the process, and minimizes the need for human involvement during model development.