Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmentation of base classifier performance via HMMs on a handwritten character data set
Paper and Code
Nov 17, 2021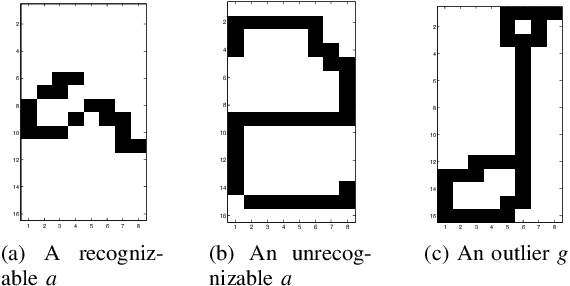
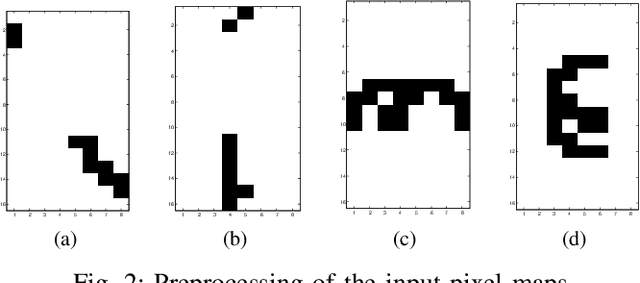
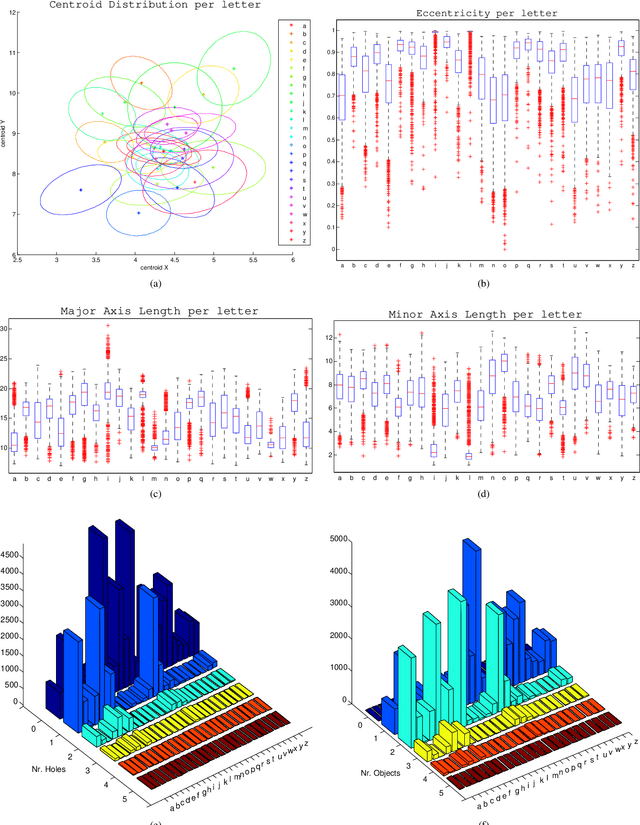
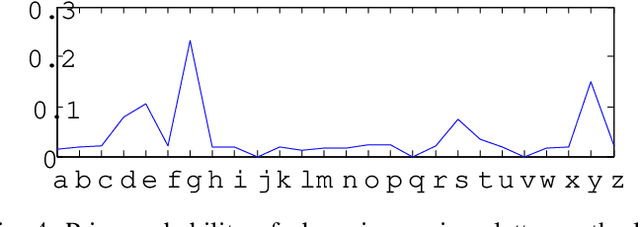
This paper presents results of a study of the performance of several base classifiers for recognition of handwritten characters of the modern Latin alphabet. Base classification performance is further enhanced by utilizing Viterbi error correction by determining the Viterbi sequence. Hidden Markov Models (HMMs) models exploit relationships between letters within a word to determine the most likely sequence of characters. Four base classifiers are studied along with eight feature sets extracted from the handwritten dataset. The best classification performance after correction was 89.8%, and the average was 68.1%
View paper on