 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-Visual Target Speaker Extraction on Multi-Talker Environment using Event-Driven Cameras
Paper and Code
Dec 05, 2019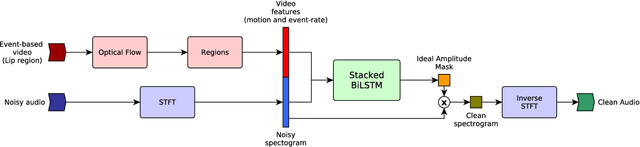

In this work, we propose a new method to address audio-visual target speaker extraction in multi-talker environments using event-driven cameras. All audio-visual speech separation approaches use a frame-based video to extract visual features. However, these frame-based cameras usually work at 30 frames per second. This limitation makes it difficult to process an audio-visual signal with low latency. In order to overcome this limitation, we propose using event-driven cameras due to their high temporal resolution and low latency. Recent work showed that the use of landmark motion features is very important in order to get good results on audio-visual speech separation. Thus, we use event-driven vision sensors from which the extraction of motion is available at lower latency computational cost. A stacked Bidirectional LSTM is trained to predict an Ideal Amplitude Mask before post-processing to get a clean audio signal. The performance of our model is close to those yielded in frame-based fashion.