 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-Guided Fusion Techniques for Multimodal Emotion Analysis
Paper and Code
Sep 08, 2024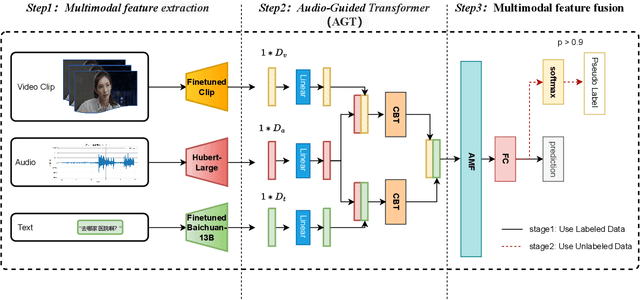
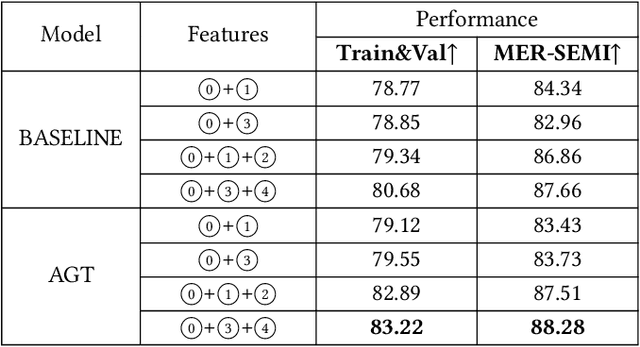
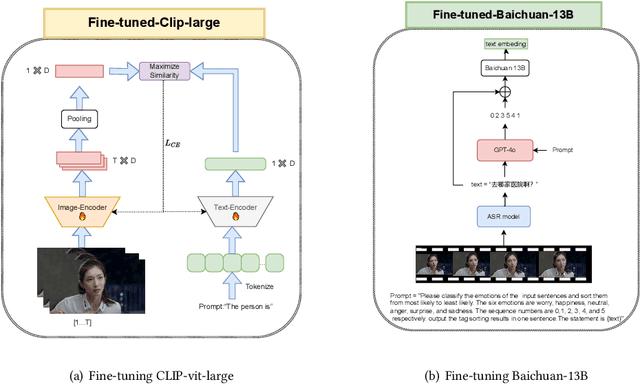
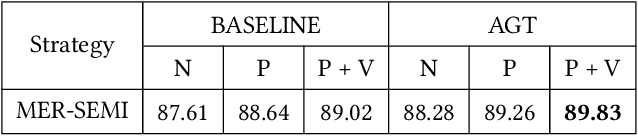
In this paper, we propose a solution for the semi-supervised learning track (MER-SEMI) in MER2024. First, in order to enhance the performance of the feature extractor on sentiment classification tasks,we fine-tuned video and text feature extractors, specifically CLIP-vit-large and Baichuan-13B, using labeled data. This approach effectively preserves the original emotional information conveyed in the videos. Second, we propose an Audio-Guided Transformer (AGT) fusion mechanism, which leverages the robustness of Hubert-large, showing superior effectiveness in fusing both inter-channel and intra-channel information. Third, To enhance the accuracy of the model, we iteratively apply self-supervised learning by using high-confidence unlabeled data as pseudo-labels. Finally, through black-box probing, we discovered an imbalanced data distribution between the training and test sets. Therefore, We adopt a prior-knowledge-based voting mechanism. The results demonstrate the effectiveness of our strategy, ultimately earning us third place in the MER-SEMI track.