 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttentive Convolutional Neural Network based Speech Emotion Recognition: A Study on the Impact of Input Features, Signal Length, and Acted Speech
Paper and Code
Jun 02, 2017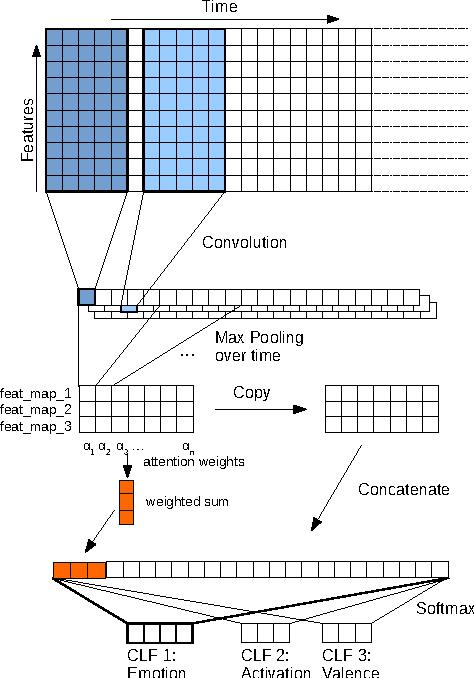
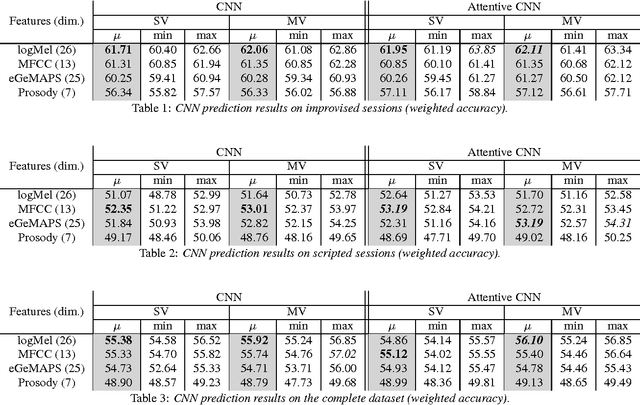
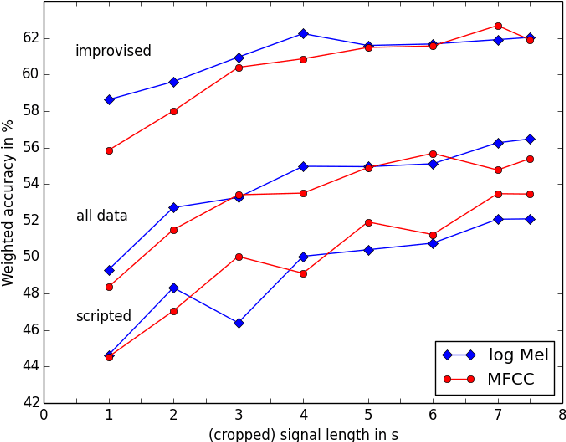
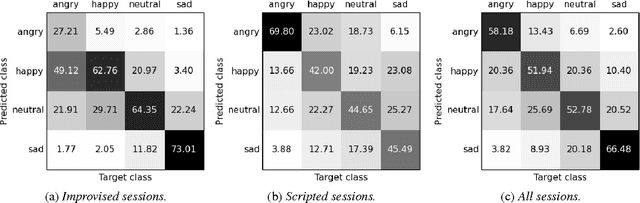
Speech emotion recognition is an important and challenging task in the realm of human-computer interaction. Prior work proposed a variety of models and feature sets for training a system. In this work, we conduct extensive experiments using an attentive convolutional neural network with multi-view learning objective function. We compare system performance using different lengths of the input signal, different types of acoustic features and different types of emotion speech (improvised/scripted). Our experimental results on the Interactive Emotional Motion Capture (IEMOCAP) database reveal that the recognition performance strongly depends on the type of speech data independent of the choice of input features. Furthermore, we achieved state-of-the-art results on the improvised speech data of IEMOCAP.