Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Beam: An Image Captioning Approach
Paper and Code
Nov 11, 2020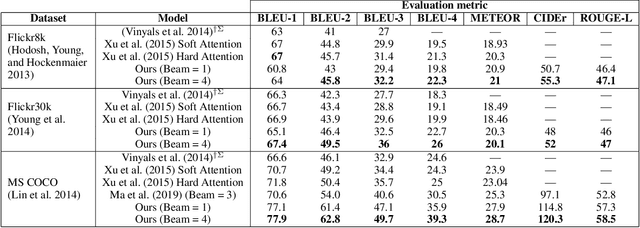
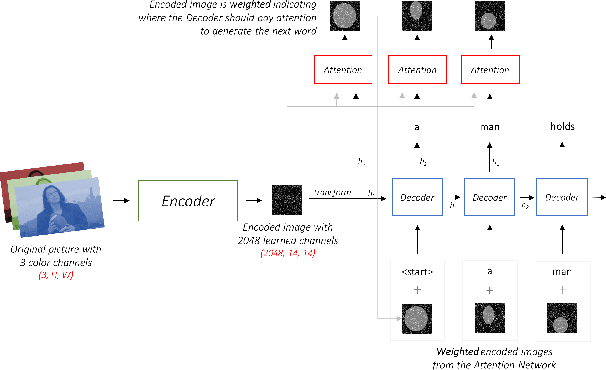
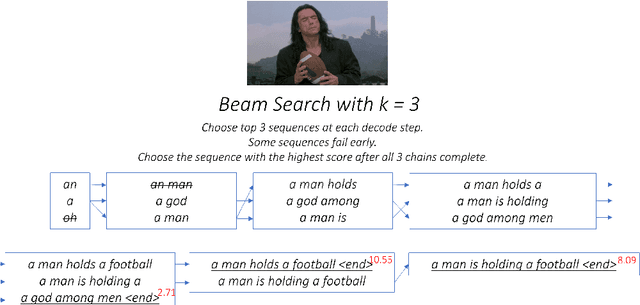
The aim of image captioning is to generate textual description of a given image. Though seemingly an easy task for humans, it is challenging for machines as it requires the ability to comprehend the image (computer vision) and consequently generate a human-like description for the image (natural language understanding). In recent times, encoder-decoder based architectures have achieved state-of-the-art results for image captioning. Here, we present a heuristic of beam search on top of the encoder-decoder based architecture that gives better quality captions on three benchmark datasets: Flickr8k, Flickr30k and MS COCO.
* 5 pages, 6 figures, 1 table, in Proceedings of the 35th AAAI
Conference on Artificial Intelligence (AAAI-21) Student Abstract
View paper on