 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsymmetrical Vertical Federated Learning
Paper and Code
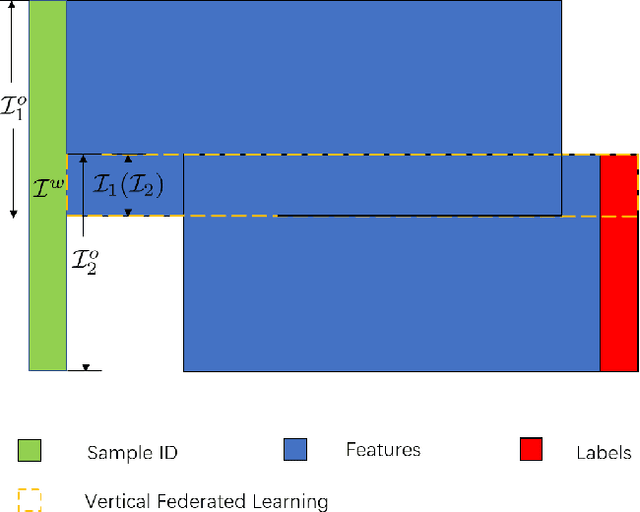


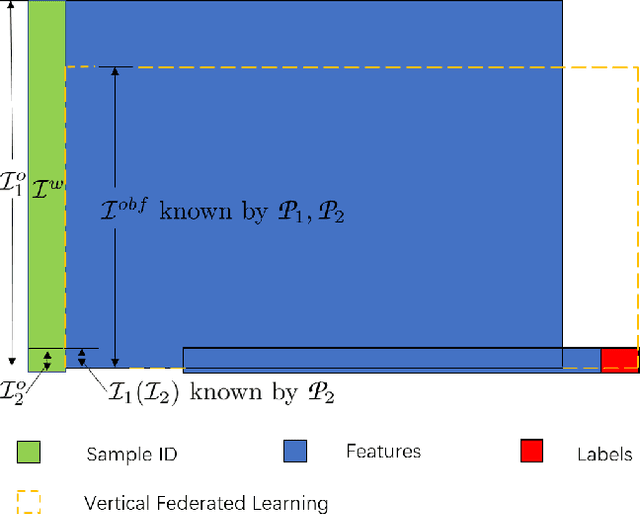
Federated learning is a distributed machine learning method that aims to preserve the privacy of sample features and labels. In a federated learning system, ID-based sample alignment approaches are usually applied with few efforts made on the protection of ID privacy. In real-life applications, however, the confidentiality of sample IDs, which are the strongest row identifiers, is also drawing much attention from many participants. To relax their privacy concerns about ID privacy, this paper formally proposes the notion of asymmetrical vertical federated learning and illustrates the way to protect sample IDs. The standard private set intersection protocol is adapted to achieve the asymmetrical ID alignment phase in an asymmetrical vertical federated learning system. Correspondingly, a Pohlig-Hellman realization of the adapted protocol is provided. This paper also presents a genuine with dummy approach to achieving asymmetrical federated model training. To illustrate its application, a federated logistic regression algorithm is provided as an example. Experiments are also made for validating the feasibility of this approach.