 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsymmetric Shapley values: incorporating causal knowledge into model-agnostic explainability
Paper and Code
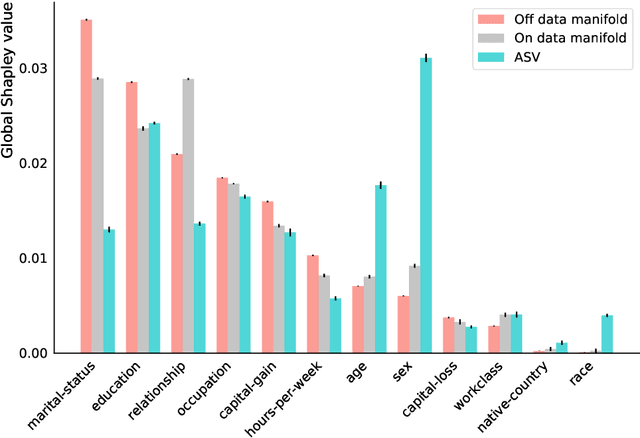
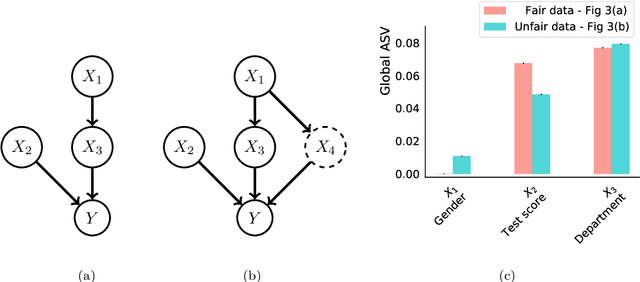
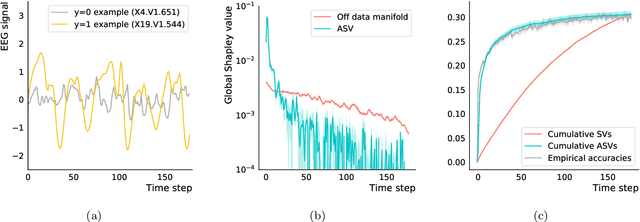
Explaining AI systems is fundamental both to the development of high performing models and to the trust placed in them by their users. A general framework for explaining any AI model is provided by the Shapley values that attribute the prediction output to the various model inputs ("features") in a principled and model-agnostic way. The outstanding strength of Shapley values is their combined generality and rigorous foundation: they can be used to explain any AI system, and one always understands their values as the unique attribution method satisfying a set of mathematical axioms. However, as a framework, Shapley values are too restrictive in one significant regard: they ignore all causal structure in the data. We introduce a less-restrictive framework for model-agnostic explainability: "Asymmetric" Shapley values. Asymmetric Shapley values (ASVs) are rigorously founded on a set of axioms, applicable to any AI system, and can flexibly incorporate any causal knowledge known a-priori to be respected by the data. We show through explicit, realistic examples that the ASV framework can be used to (i) improve model explanations by incorporating causal information, (ii) provide an unambiguous test for unfair discrimination based on simple policy articulations, (iii) enable sequentially incremental explanations in time-series models, and (iv) support feature-selection studies without the need for model retraining.