 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Sufficiency of Arguments through Conclusion Generation
Paper and Code


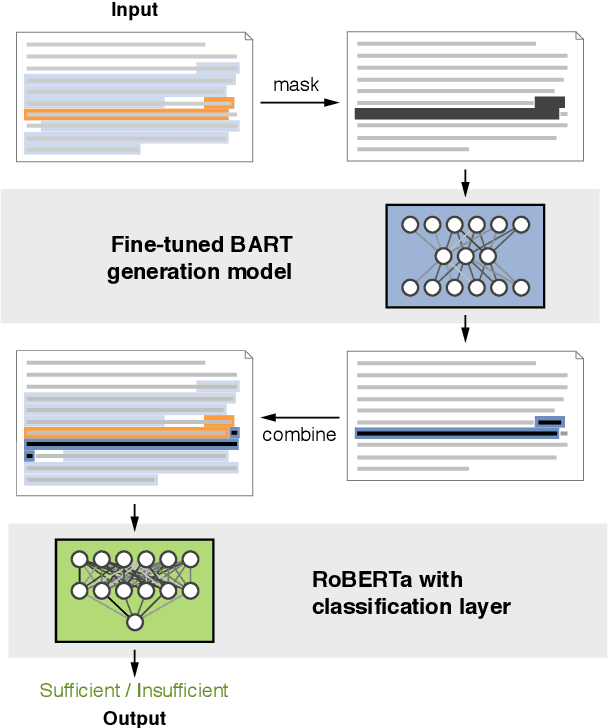

The premises of an argument give evidence or other reasons to support a conclusion. However, the amount of support required depends on the generality of a conclusion, the nature of the individual premises, and similar. An argument whose premises make its conclusion rationally worthy to be drawn is called sufficient in argument quality research. Previous work tackled sufficiency assessment as a standard text classification problem, not modeling the inherent relation of premises and conclusion. In this paper, we hypothesize that the conclusion of a sufficient argument can be generated from its premises. To study this hypothesis, we explore the potential of assessing sufficiency based on the output of large-scale pre-trained language models. Our best model variant achieves an F1-score of .885, outperforming the previous state-of-the-art and being on par with human experts. While manual evaluation reveals the quality of the generated conclusions, their impact remains low ultimately.