 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Transformer with Multi-View Visual Representation for Image Captioning
Paper and Code
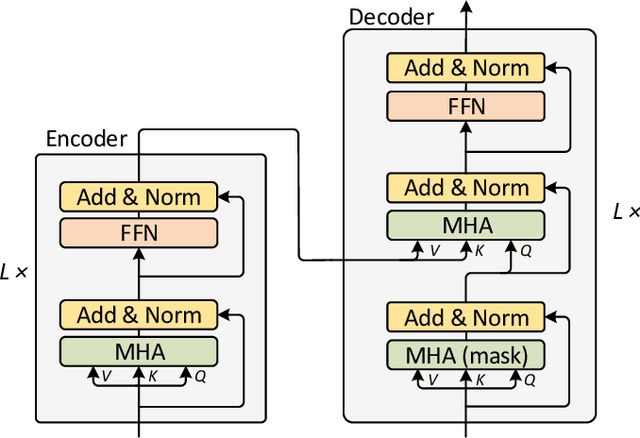
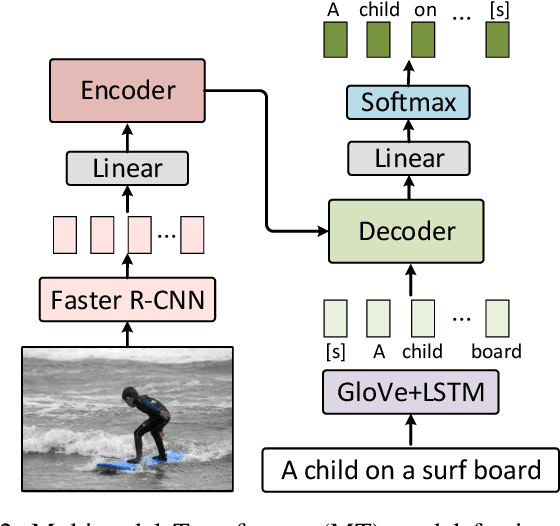


Image captioning aims to automatically generate a natural language description of a given image, and most state-of-the-art models have adopted an encoder-decoder framework. The framework consists of a convolution neural network (CNN)-based image encoder that extracts region-based visual features from the input image, and an recurrent neural network (RNN)-based caption decoder that generates the output caption words based on the visual features with the attention mechanism. Despite the success of existing studies, current methods only model the co-attention that characterizes the inter-modal interactions while neglecting the self-attention that characterizes the intra-modal interactions. Inspired by the success of the Transformer model in machine translation, here we extend it to a Multimodal Transformer (MT) model for image captioning. Compared to existing image captioning approaches, the MT model simultaneously captures intra- and inter-modal interactions in a unified attention block. Due to the in-depth modular composition of such attention blocks, the MT model can perform complex multimodal reasoning and output accurate captions. Moreover, to further improve the image captioning performance, multi-view visual features are seamlessly introduced into the MT model. We quantitatively and qualitatively evaluate our approach using the benchmark MSCOCO image captioning dataset and conduct extensive ablation studies to investigate the reasons behind its effectiveness. The experimental results show that our method significantly outperforms the previous state-of-the-art methods. With an ensemble of seven models, our solution ranks the 1st place on the real-time leaderboard of the MSCOCO image captioning challenge at the time of the writing of this paper.