Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApprenticeship Learning using Inverse Reinforcement Learning and Gradient Methods
Paper and Code
Jun 20, 2012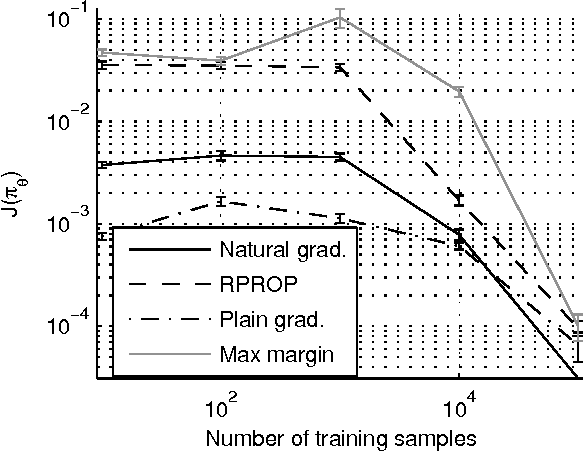



In this paper we propose a novel gradient algorithm to learn a policy from an expert's observed behavior assuming that the expert behaves optimally with respect to some unknown reward function of a Markovian Decision Problem. The algorithm's aim is to find a reward function such that the resulting optimal policy matches well the expert's observed behavior. The main difficulty is that the mapping from the parameters to policies is both nonsmooth and highly redundant. Resorting to subdifferentials solves the first difficulty, while the second one is over- come by computing natural gradients. We tested the proposed method in two artificial domains and found it to be more reliable and efficient than some previous methods.
* Appears in Proceedings of the Twenty-Third Conference on Uncertainty
in Artificial Intelligence (UAI2007)
View paper on