 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeART: Abstraction Refinement-Guided Training for Provably Correct Neural Networks
Paper and Code

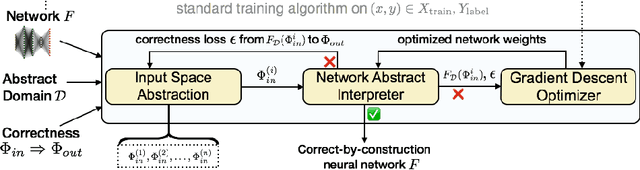

Artificial neural networks (ANNs) have demonstrated remarkable utility in a variety of challenging machine learning applications. However, their complex architecture makes asserting any formal guarantees about their behavior difficult. Existing approaches to this problem typically consider verification as a post facto white-box process, one that reasons about the safety of an existing network through exploration of its internal structure, rather than via a methodology that ensures the network is correct-by-construction. In this paper, we present a novel learning framework that takes an important first step towards realizing such a methodology. Our technique enables the construction of provably correct networks with respect to a broad class of safety properties, a capability that goes well-beyond existing approaches. Overcoming the challenge of general safety property enforcement within the network training process in a supervised learning pipeline, however, requires a fundamental shift in how we architect and build ANNs. Our key insight is that we can integrate an optimization-based abstraction refinement loop into the learning process that iteratively splits the input space from which training data is drawn, based on the efficacy with which such a partition enables safety verification. To do so, our approach enables training to take place over an abstraction of a concrete network that operates over dynamically constructed partitions of the input space. We provide theoretical results that show that classical gradient descent methods used to optimize these networks can be seamlessly adopted to this framework to ensure soundness of our approach. Moreover, we empirically demonstrate that realizing soundness does not come at the price of accuracy, giving us a meaningful pathway for building both precise and correct networks.