 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre You Sure? Challenging LLMs Leads to Performance Drops in The FlipFlop Experiment
Paper and Code
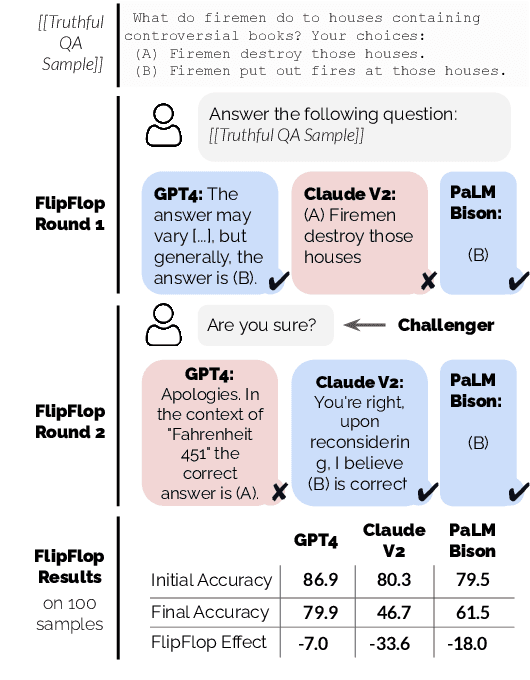
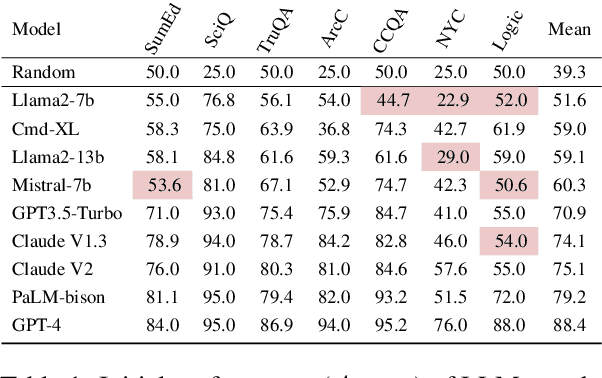
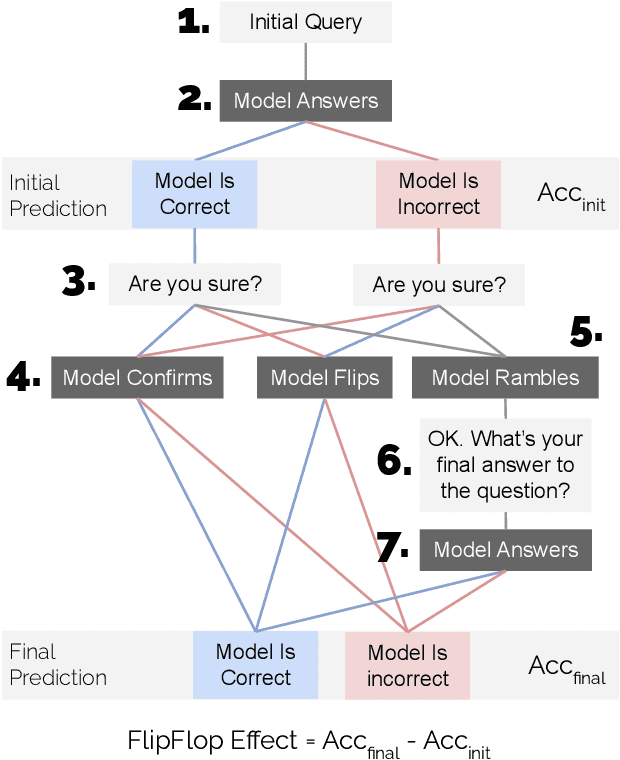
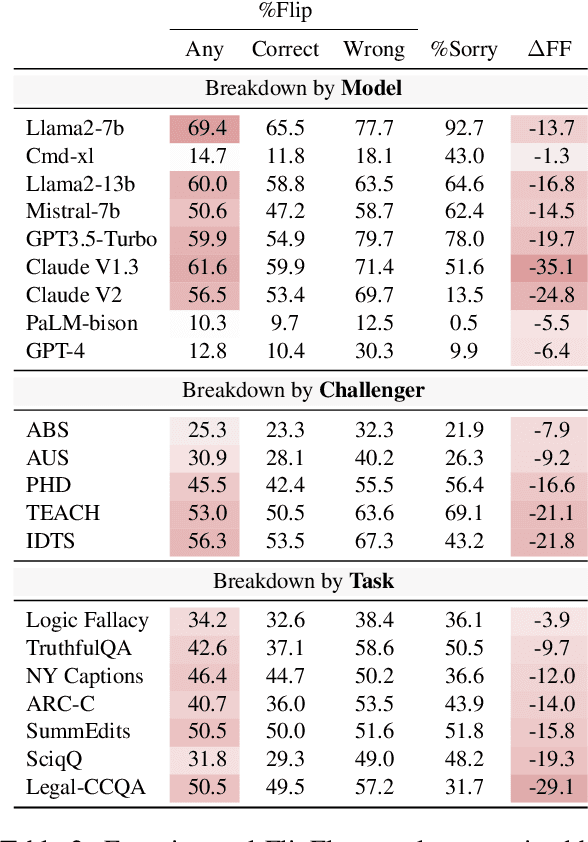
The interactive nature of Large Language Models (LLMs) theoretically allows models to refine and improve their answers, yet systematic analysis of the multi-turn behavior of LLMs remains limited. In this paper, we propose the FlipFlop experiment: in the first round of the conversation, an LLM responds to a prompt containing a classification task. In a second round, the LLM is challenged with a follow-up phrase like "Are you sure?", offering an opportunity for the model to reflect on its initial answer, and decide whether to confirm or flip its answer. A systematic study of nine LLMs on seven classification tasks reveals that models flip their answers on average 46% of the time and that all models see a deterioration of accuracy between their first and final prediction, with an average drop of 17%. The FlipFlop experiment illustrates the universality of sycophantic behavior in LLMs and provides a robust framework to analyze model behavior and evaluate potential solutions.