Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre foundation models efficient for medical image segmentation?
Paper and Code
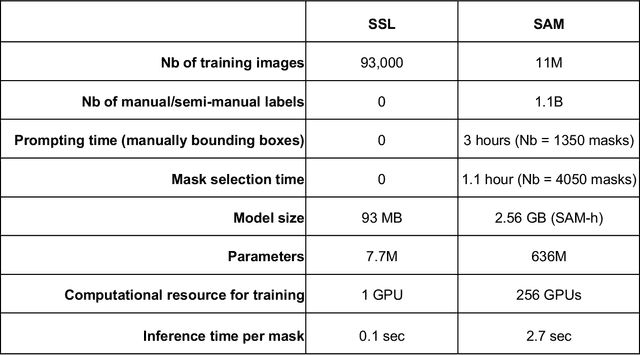

Foundation models are experiencing a surge in popularity. The Segment Anything model (SAM) asserts an ability to segment a wide spectrum of objects but required supervised training at unprecedented scale. We compared SAM's performance (against clinical ground truth) and resources (labeling time, compute) to a modality-specific, label-free self-supervised learning (SSL) method on 25 measurements for 100 cardiac ultrasounds. SAM performed poorly and required significantly more labeling and computing resources, demonstrating worse efficiency than SSL.
* 14 pages, 2 figures, 2 tables
View paper on