 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximation Power of Deep Neural Networks: an explanatory mathematical survey
Paper and Code
Jul 19, 2022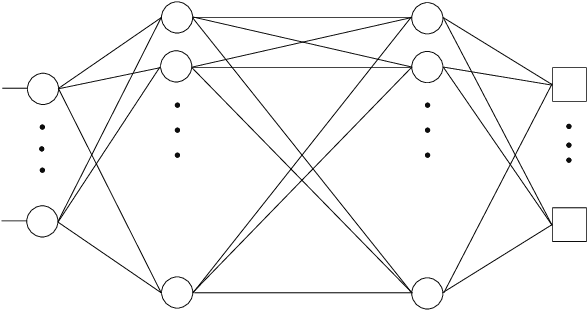


The goal of this survey is to present an explanatory review of the approximation properties of deep neural networks. Specifically, we aim at understanding how and why deep neural networks outperform other classical linear and nonlinear approximation methods. This survey consists of three chapters. In Chapter 1 we review the key ideas and concepts underlying deep networks and their compositional nonlinear structure. We formalize the neural network problem by formulating it as an optimization problem when solving regression and classification problems. We briefly discuss the stochastic gradient descent algorithm and the back-propagation formulas used in solving the optimization problem and address a few issues related to the performance of neural networks, including the choice of activation functions, cost functions, overfitting issues, and regularization. In Chapter 2 we shift our focus to the approximation theory of neural networks. We start with an introduction to the concept of density in polynomial approximation and in particular study the Stone-Weierstrass theorem for real-valued continuous functions. Then, within the framework of linear approximation, we review a few classical results on the density and convergence rate of feedforward networks, followed by more recent developments on the complexity of deep networks in approximating Sobolev functions. In Chapter 3, utilizing nonlinear approximation theory, we further elaborate on the power of depth and approximation superiority of deep ReLU networks over other classical methods of nonlinear approximation.