 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximation for Probability Distributions by Wasserstein GAN
Paper and Code
Mar 18, 2021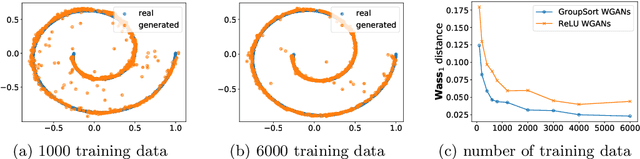


In this paper, we show that the approximation for distributions by Wasserstein GAN depends on both the width/depth (capacity) of generators and discriminators, as well as the number of samples in training. A quantified generalization bound is developed for Wasserstein distance between the generated distribution and the target distribution. It implies that with sufficient training samples, for generators and discriminators with proper number of width and depth, the learned Wasserstein GAN can approximate distributions well. We discover that discriminators suffer a lot from the curse of dimensionality, meaning that GANs have higher requirement for the capacity of discriminators than generators, which is consistent with the theory in arXiv:1703.00573v5 [cs.LG]. More importantly, overly deep (high capacity) generators may cause worse results (after training) than low capacity generators if discriminators are not strong enough. Different from Wasserstein GAN in arXiv:1701.07875v3 [stat.ML], we adopt GroupSort neural networks arXiv:1811.05381v2 [cs.LG] in the model for their better approximation to 1-Lipschitz functions. Compared to some existing generalization (convergence) analysis of GANs, we expect our work are more applicable.