 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximating Spectral Clustering via Sampling: a Review
Paper and Code
Jan 29, 2019
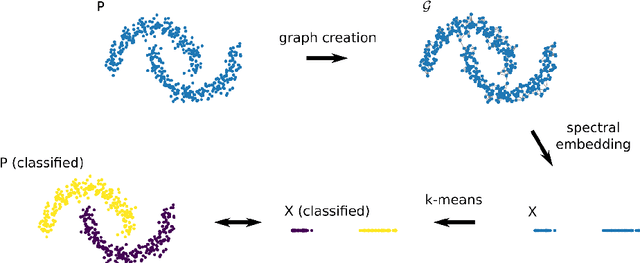
Spectral clustering refers to a family of unsupervised learning algorithms that compute a spectral embedding of the original data based on the eigenvectors of a similarity graph. This non-linear transformation of the data is both the key of these algorithms' success and their Achilles heel: forming a graph and computing its dominant eigenvectors can indeed be computationally prohibitive when dealing with more that a few tens of thousands of points. In this paper, we review the principal research efforts aiming to reduce this computational cost. We focus on methods that come with a theoretical control on the clustering performance and incorporate some form of sampling in their operation. Such methods abound in the machine learning, numerical linear algebra, and graph signal processing literature and, amongst others, include Nystr\"om-approximation, landmarks, coarsening, coresets, and compressive spectral clustering. We present the approximation guarantees available for each and discuss practical merits and limitations. Surprisingly, despite the breadth of the literature explored, we conclude that there is still a gap between theory and practice: the most scalable methods are only intuitively motivated or loosely controlled, whereas those that come with end-to-end guarantees rely on strong assumptions or enable a limited gain of computation time.