 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproaching the linguistic complexity
Paper and Code
Jan 21, 2009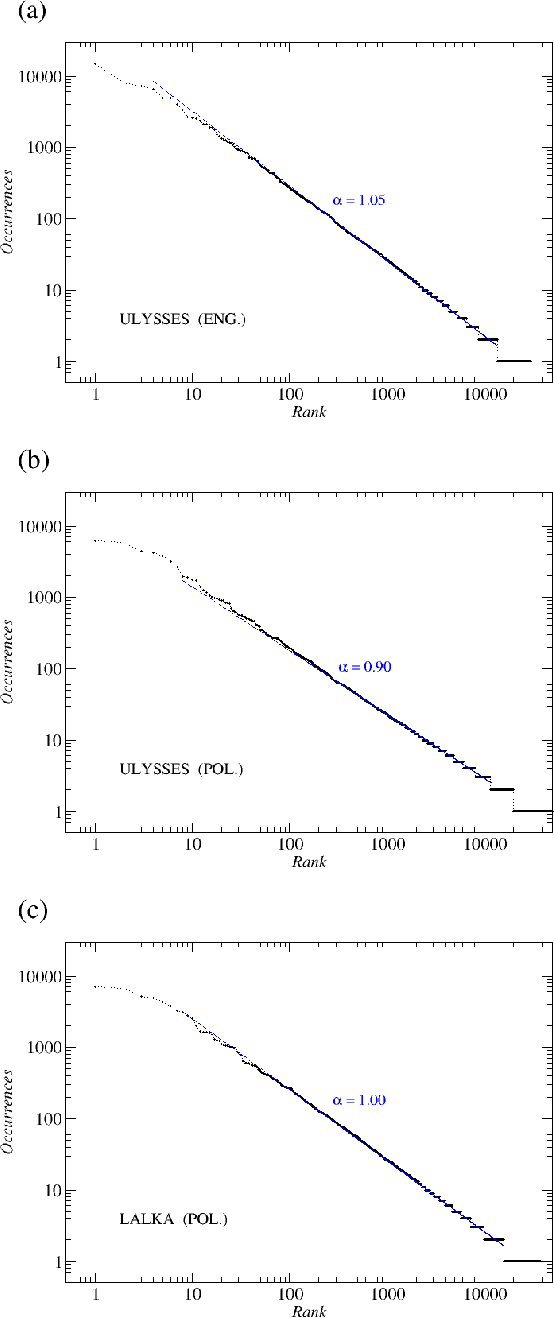
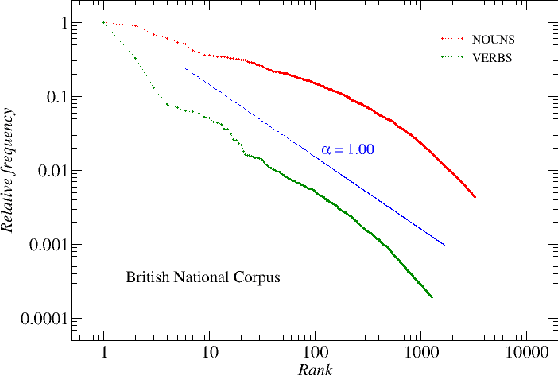
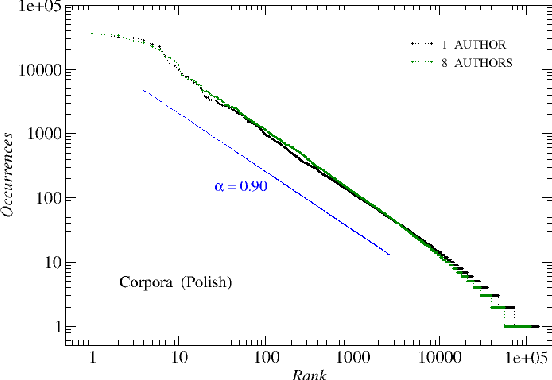
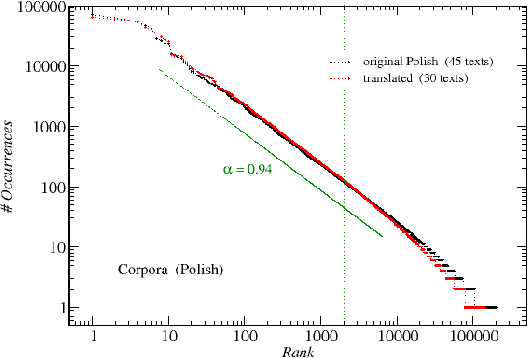
We analyze the rank-frequency distributions of words in selected English and Polish texts. We compare scaling properties of these distributions in both languages. We also study a few small corpora of Polish literary texts and find that for a corpus consisting of texts written by different authors the basic scaling regime is broken more strongly than in the case of comparable corpus consisting of texts written by the same author. Similarly, for a corpus consisting of texts translated into Polish from other languages the scaling regime is broken more strongly than for a comparable corpus of native Polish texts. Moreover, based on the British National Corpus, we consider the rank-frequency distributions of the grammatically basic forms of words (lemmas) tagged with their proper part of speech. We find that these distributions do not scale if each part of speech is analyzed separately. The only part of speech that independently develops a trace of scaling is verbs.