 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplication of linear regression method to the deep reinforcement learning in continuous action cases
Paper and Code
Mar 21, 2025

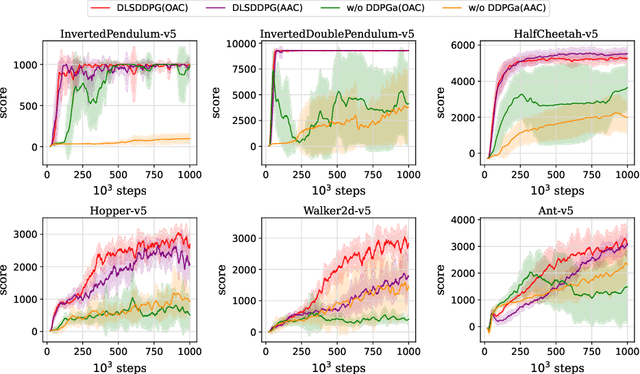

The linear regression (LR) method offers the advantage that optimal parameters can be calculated relatively easily, although its representation capability is limited than that of the deep learning technique. To improve deep reinforcement learning, the Least Squares Deep Q Network (LS-DQN) method was proposed by Levine et al., which combines Deep Q Network (DQN) with LR method. However, the LS-DQN method assumes that the actions are discrete. In this study, we propose the Double Least Squares Deep Deterministic Policy Gradient (DLS-DDPG) method to address this limitation. This method combines the LR method with the Deep Deterministic Policy Gradient (DDPG) technique, one of the representative deep reinforcement learning algorithms for continuous action cases. Numerical experiments conducted in MuJoCo environments showed that the LR update improved performance at least in some tasks, although there are difficulties such as the inability to make the regularization terms small.