 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeANTNets: Mobile Convolutional Neural Networks for Resource Efficient Image Classification
Paper and Code
Apr 07, 2019
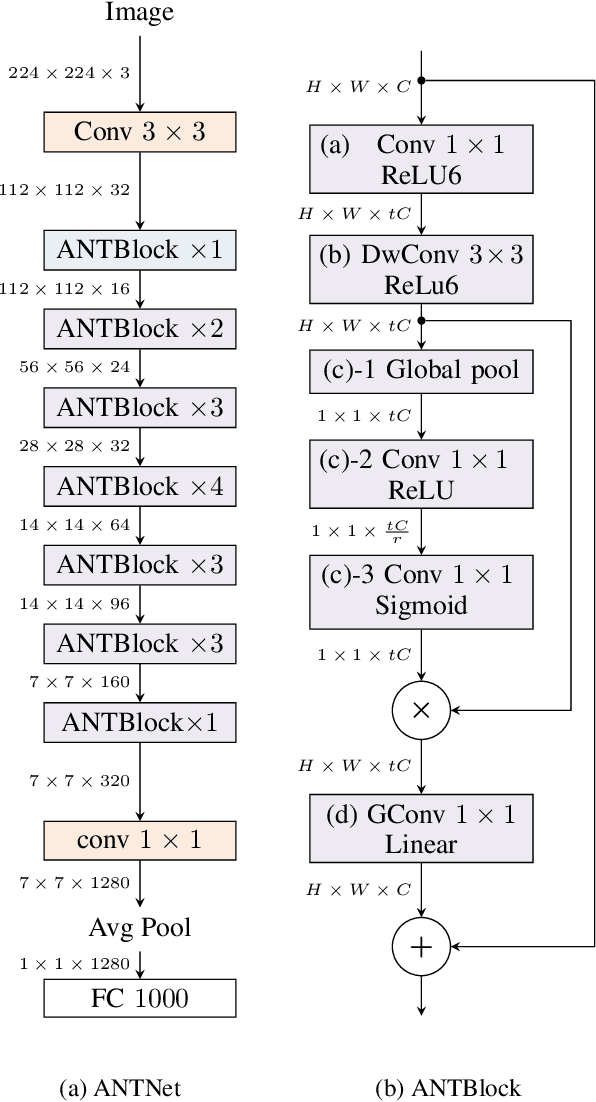
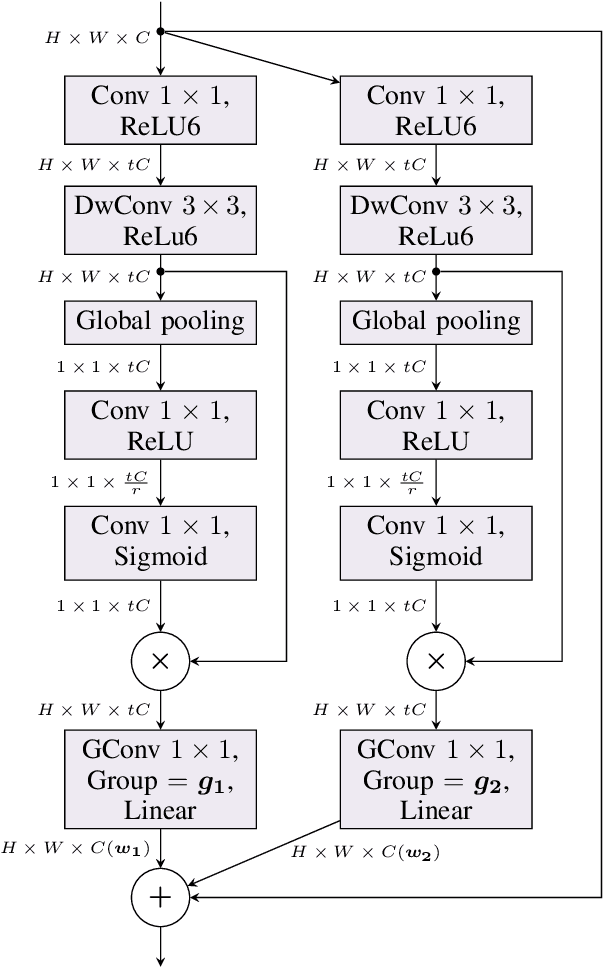
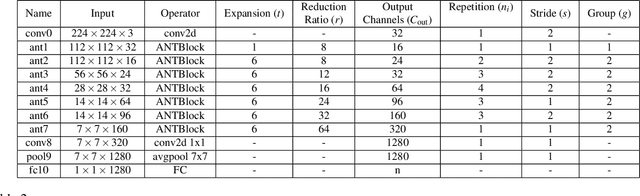
Deep convolutional neural networks have achieved remarkable success in computer vision. However, deep neural networks require large computing resources to achieve high performance. Although depthwise separable convolution can be an efficient module to approximate a standard convolution, it often leads to reduced representational power of networks. In this paper, under budget constraints such as computational cost (MAdds) and the parameter count, we propose a novel basic architectural block, ANTBlock. It boosts the representational power by modeling, in a high dimensional space, interdependency of channels between a depthwise convolution layer and a projection layer in the ANTBlocks. Our experiments show that ANTNet built by a sequence of ANTBlocks, consistently outperforms state-of-the-art low-cost mobile convolutional neural networks across multiple datasets. On CIFAR100, our model achieves 75.7% top-1 accuracy, which is 1.5% higher than MobileNetV2 with 8.3% fewer parameters and 19.6% less computational cost. On ImageNet, our model achieves 72.8% top-1 accuracy, which is 0.8% improvement, with 157.7ms (20% faster) on iPhone 5s over MobileNetV2.