 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomaly Detection by Robust Statistics
Paper and Code
Oct 14, 2017
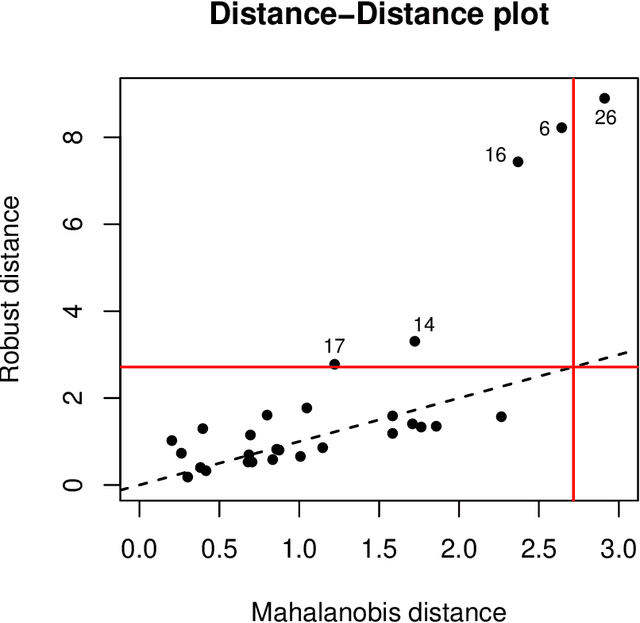

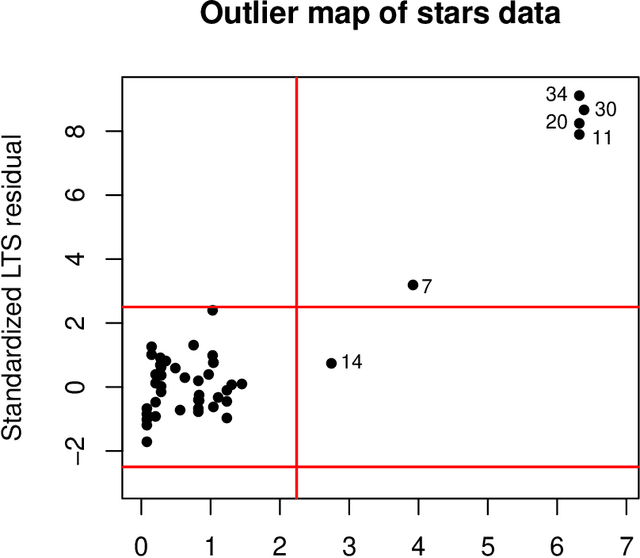
Real data often contain anomalous cases, also known as outliers. These may spoil the resulting analysis but they may also contain valuable information. In either case, the ability to detect such anomalies is essential. A useful tool for this purpose is robust statistics, which aims to detect the outliers by first fitting the majority of the data and then flagging data points that deviate from it. We present an overview of several robust methods and the resulting graphical outlier detection tools. We discuss robust procedures for univariate, low-dimensional, and high-dimensional data, such as estimating location and scatter, linear regression, principal component analysis, classification, clustering, and functional data analysis. Also the challenging new topic of cellwise outliers is introduced.