 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnimatable 3D Gaussians for High-fidelity Synthesis of Human Motions
Paper and Code
Nov 27, 2023
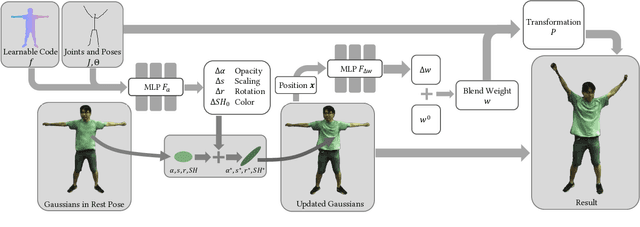
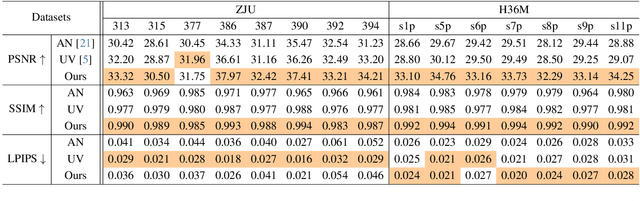
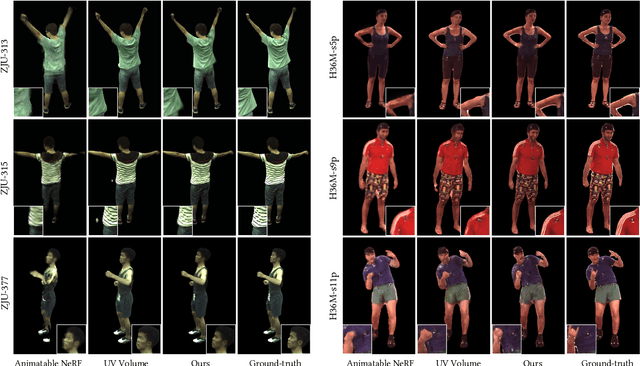
We present a novel animatable 3D Gaussian model for rendering high-fidelity free-view human motions in real time. Compared to existing NeRF-based methods, the model owns better capability in synthesizing high-frequency details without the jittering problem across video frames. The core of our model is a novel augmented 3D Gaussian representation, which attaches each Gaussian with a learnable code. The learnable code serves as a pose-dependent appearance embedding for refining the erroneous appearance caused by geometric transformation of Gaussians, based on which an appearance refinement model is learned to produce residual Gaussian properties to match the appearance in target pose. To force the Gaussians to learn the foreground human only without background interference, we further design a novel alpha loss to explicitly constrain the Gaussians within the human body. We also propose to jointly optimize the human joint parameters to improve the appearance accuracy. The animatable 3D Gaussian model can be learned with shallow MLPs, so new human motions can be synthesized in real time (66 fps on avarage). Experiments show that our model has superior performance over NeRF-based methods.