 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing the Quality Attributes of AI Vision Models in Open Repositories Under Adversarial Attacks
Paper and Code
Jan 22, 2024
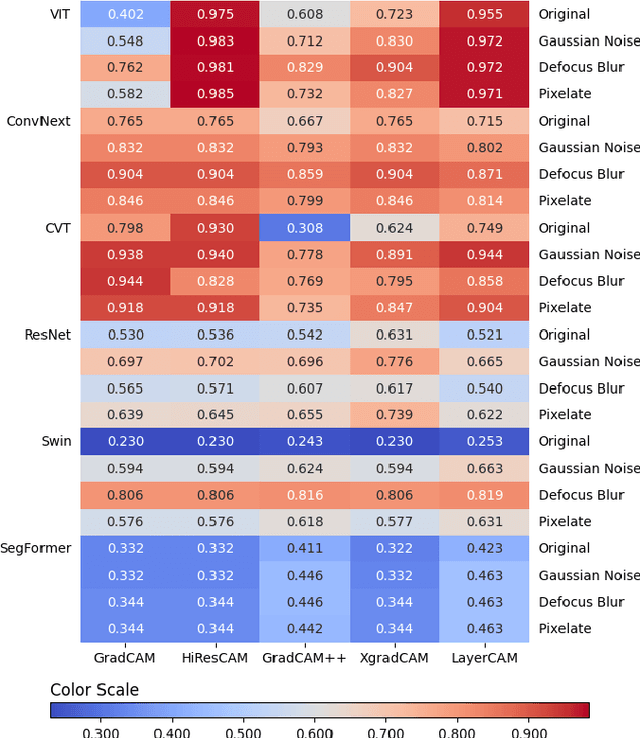


As AI models rapidly evolve, they are frequently released to open repositories, such as HuggingFace. It is essential to perform quality assurance validation on these models before integrating them into the production development lifecycle. In addition to evaluating efficiency in terms of balanced accuracy and computing costs, adversarial attacks are potential threats to the robustness and explainability of AI models. Meanwhile, XAI applies algorithms that approximate inputs to outputs post-hoc to identify the contributing features. Adversarial perturbations may also degrade the utility of XAI explanations that require further investigation. In this paper, we present an integrated process designed for downstream evaluation tasks, including validating AI model accuracy, evaluating robustness with benchmark perturbations, comparing explanation utility, and assessing overhead. We demonstrate an evaluation scenario involving six computer vision models, which include CNN-based, Transformer-based, and hybrid architectures, three types of perturbations, and five XAI methods, resulting in ninety unique combinations. The process reveals the explanation utility among the XAI methods in terms of the identified key areas responding to the adversarial perturbation. The process produces aggregated results that illustrate multiple attributes of each AI model.