 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing the Impact of COVID-19 on Economy from the Perspective of Users Reviews
Paper and Code
Oct 05, 2021
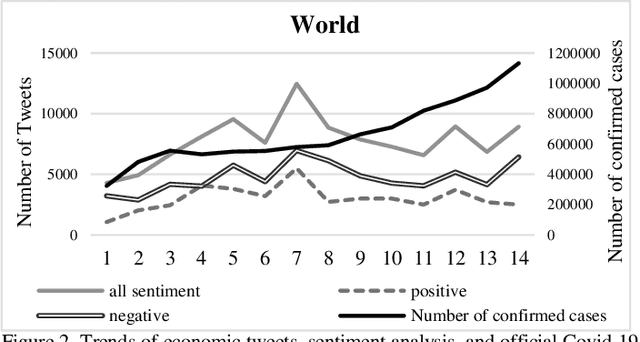
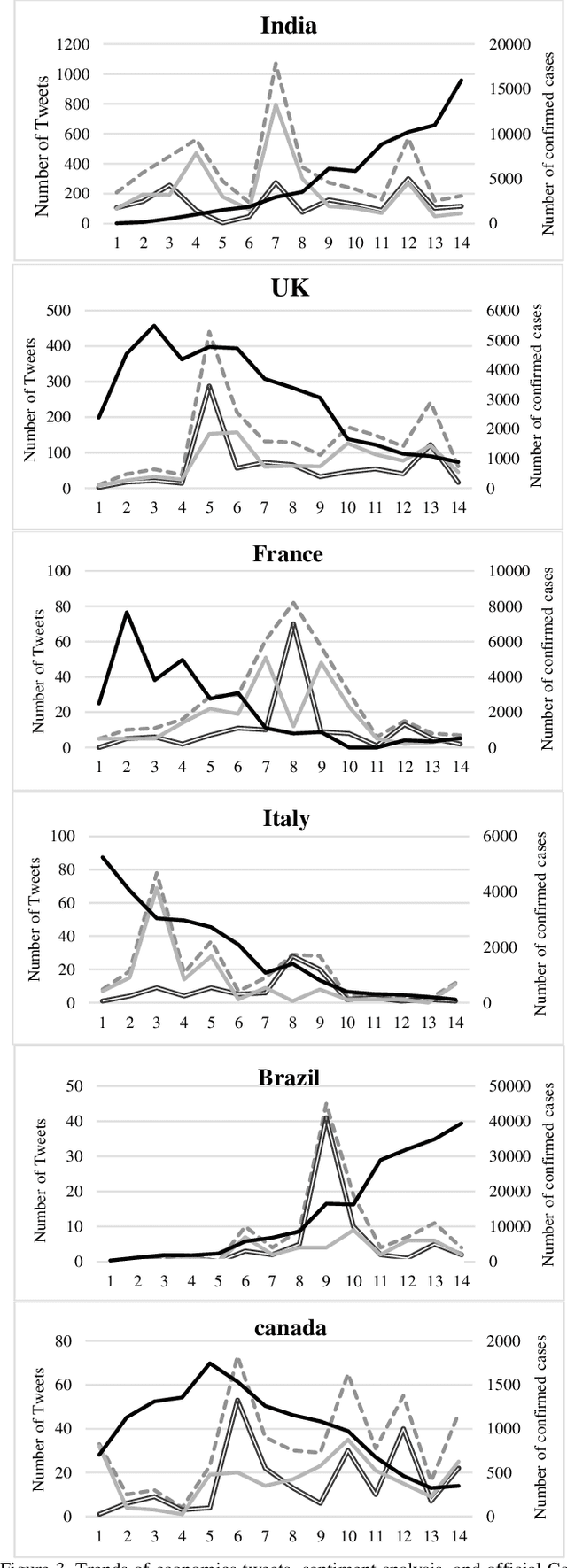
One of the most important incidents in the world in 2020 is the outbreak of the Coronavirus. Users on social networks publish a large number of comments about this event. These comments contain important hidden information of public opinion regarding this pandemic. In this research, a large number of Coronavirus-related tweets are considered and analyzed using natural language processing and information retrieval science. Initially, the location of the tweets is determined using a dictionary prepared through the Geo-Names geographic database, which contains detailed and complete information of places such as city names, streets, and postal codes. Then, using a large dictionary prepared from the terms of economics, related tweets are extracted and sentiments corresponded to tweets are analyzed with the help of the RoBERTa language-based model, which has high accuracy and good performance. Finally, the frequency chart of tweets related to the economy and their sentiment scores (positive and negative tweets) is plotted over time for the entire world and the top 10 economies. From the analysis of the charts, we learn that the reason for publishing economic tweets is not only the increase in the number of people infected with the Coronavirus but also imposed restrictions and lockdowns in countries. The consequences of these restrictions include the loss of millions of jobs and the economic downturn.