 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing the Evaluation of Cross-Lingual Knowledge Transfer in Multilingual Language Models
Paper and Code
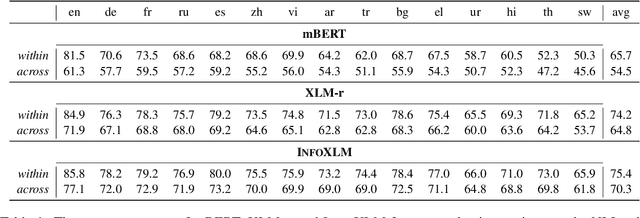
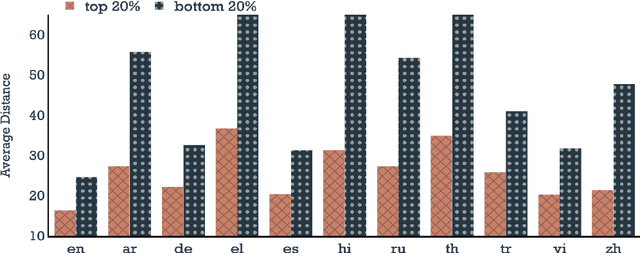
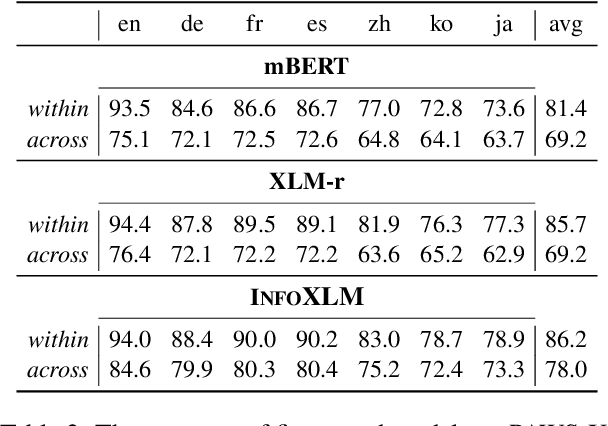

Recent advances in training multilingual language models on large datasets seem to have shown promising results in knowledge transfer across languages and achieve high performance on downstream tasks. However, we question to what extent the current evaluation benchmarks and setups accurately measure zero-shot cross-lingual knowledge transfer. In this work, we challenge the assumption that high zero-shot performance on target tasks reflects high cross-lingual ability by introducing more challenging setups involving instances with multiple languages. Through extensive experiments and analysis, we show that the observed high performance of multilingual models can be largely attributed to factors not requiring the transfer of actual linguistic knowledge, such as task- and surface-level knowledge. More specifically, we observe what has been transferred across languages is mostly data artifacts and biases, especially for low-resource languages. Our findings highlight the overlooked drawbacks of existing cross-lingual test data and evaluation setups, calling for a more nuanced understanding of the cross-lingual capabilities of multilingual models.