 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalytic Network Learning
Paper and Code
Nov 20, 2018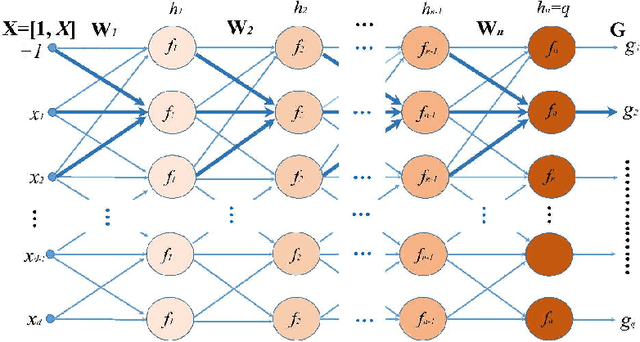



Based on the property that solving the system of linear matrix equations via the column space and the row space projections boils down to an approximation in the least squares error sense, a formulation for learning the weight matrices of the multilayer network can be derived. By exploiting into the vast number of feasible solutions of these interdependent weight matrices, the learning can be performed analytically layer by layer without needing of gradient computation after an initialization. Possible initialization schemes include utilizing the data matrix as initial weights and random initialization. The study is followed by an investigation into the representation capability and the output variance of the learning scheme. An extensive experimentation on synthetic and real-world data sets validates its numerical feasibility.