 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis Social Sparsity Audio Declipper
Paper and Code
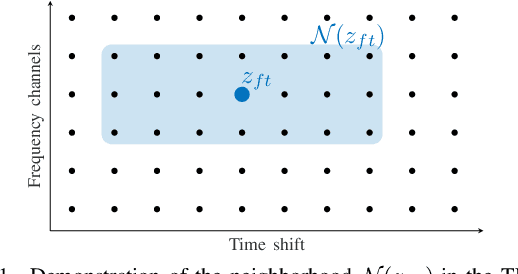
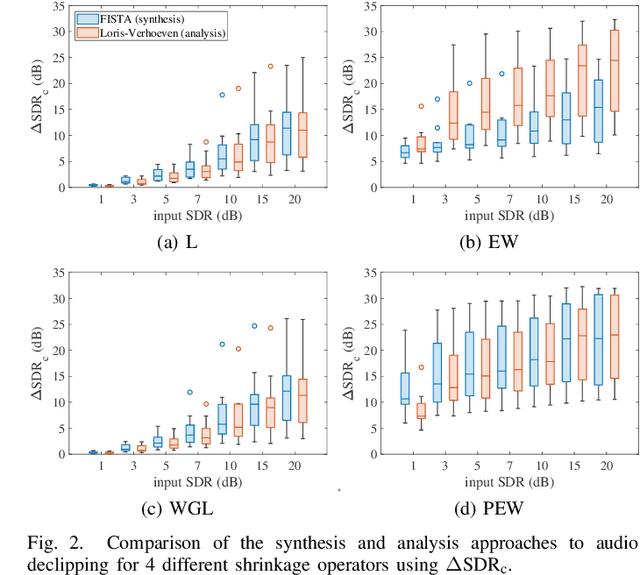
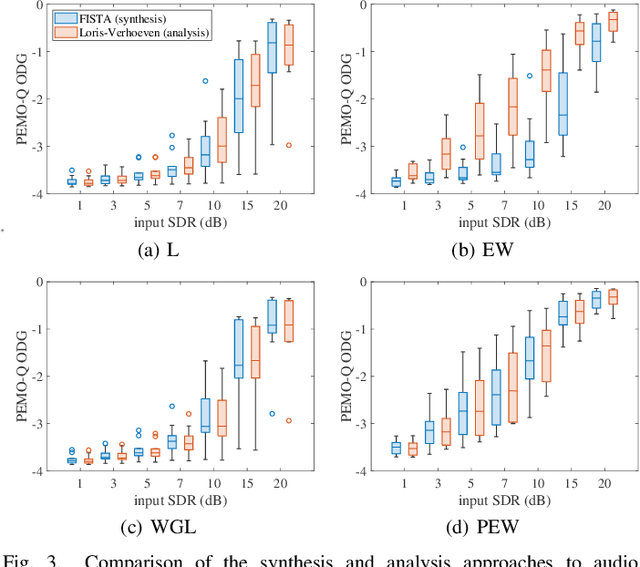
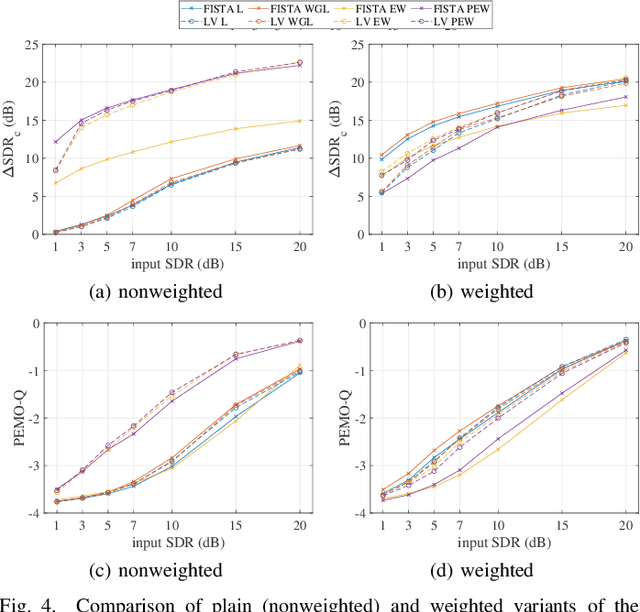
We develop the analysis (cosparse) variant of the popular audio declipping algorithm of Siedenburg et al. Furthermore, we extend it by the possibility of weighting the time-frequency coefficients. We examine the audio reconstruction performance of several combinations of weights and shrinkage operators. We show that weights improve the reconstruction quality in some cases; however, the overall scores achieved by the non-weighted are not surpassed. Yet, the analysis Empirical Wiener (EW) shrinkage was able to reach the quality of a computationally more expensive competitor, the Persistent Empirical Wiener (PEW). Moreover, the proposed analysis variant using PEW slightly outperforms the synthesis counterpart in terms of an auditory-motivated metric.