Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of the Ethiopic Twitter Dataset for Abusive Speech in Amharic
Paper and Code

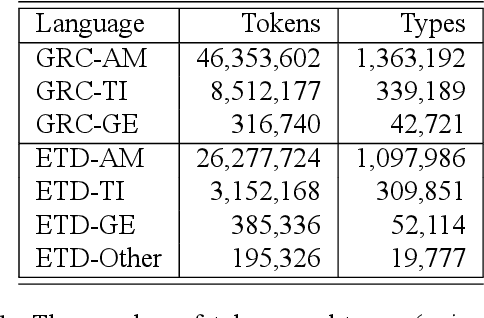
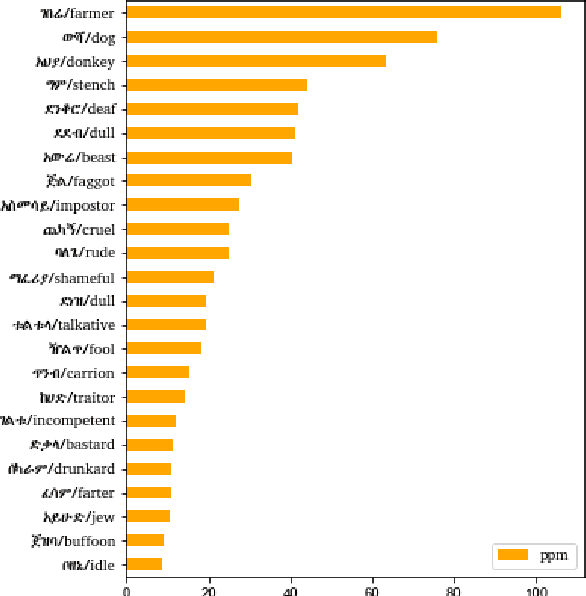

In this paper, we present an analysis of the first Ethiopic Twitter Dataset for the Amharic language targeted for recognizing abusive speech. The dataset has been collected since 2014 that is written in Fidel script. Since several languages can be written using the Fidel script, we have used the existing Amharic, Tigrinya and Ge'ez corpora to retain only the Amharic tweets. We have analyzed the tweets for abusive speech content with the following targets: Analyze the distribution and tendency of abusive speech content over time and compare the abusive speech content between a Twitter and general reference Amharic corpus.
View paper on