Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of Latent-Space Motion for Collaborative Intelligence
Paper and Code
Feb 08, 2021

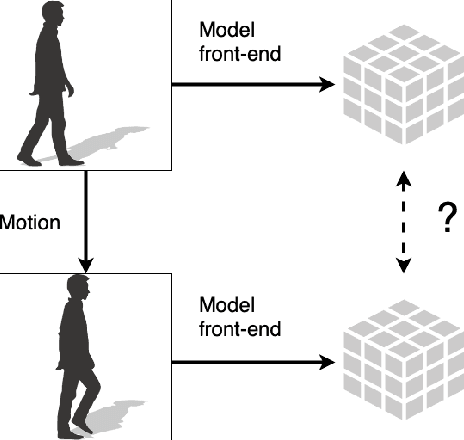
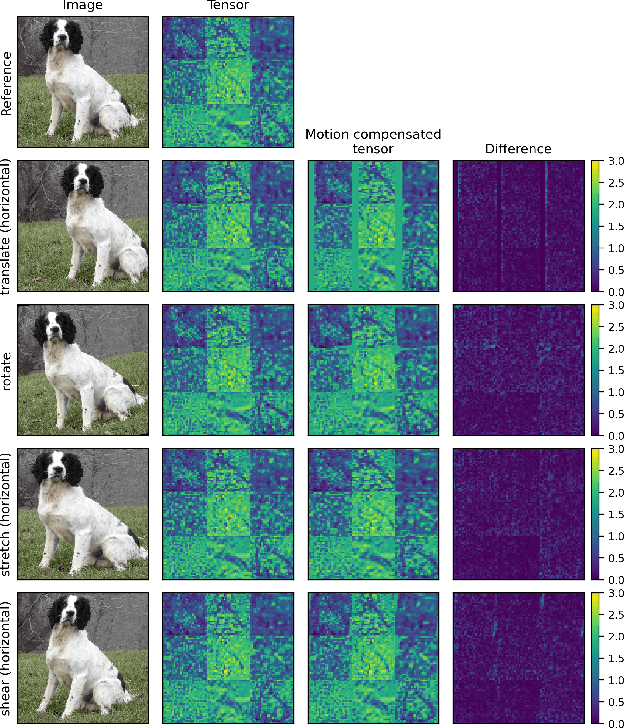
When the input to a deep neural network (DNN) is a video signal, a sequence of feature tensors is produced at the intermediate layers of the model. If neighboring frames of the input video are related through motion, a natural question is, "what is the relationship between the corresponding feature tensors?" By analyzing the effect of common DNN operations on optical flow, we show that the motion present in each channel of a feature tensor is approximately equal to the scaled version of the input motion. The analysis is validated through experiments utilizing common motion models. %These results will be useful in collaborative intelligence applications where sequences of feature tensors need to be compressed or further analyzed.
* 6 pages, 6 figures, extended version of an IEEE ICASSP 2021 paper
View paper on