 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis and Comparison of Classification Metrics
Paper and Code
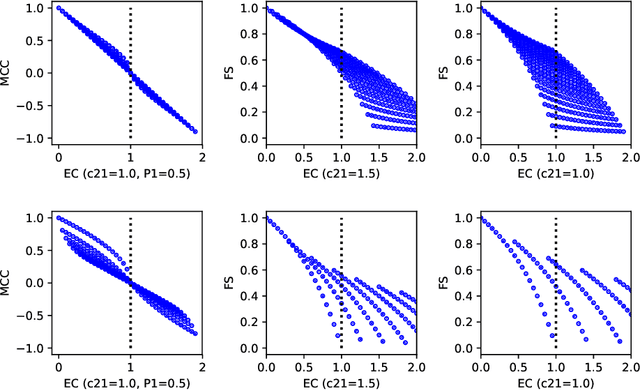
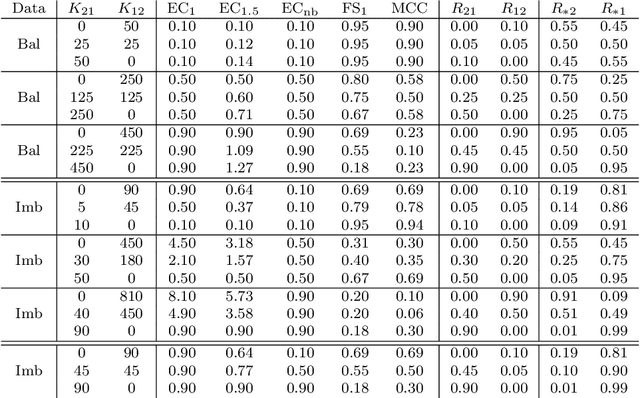
A number of different performance metrics are commonly used in the machine learning literature for classification systems that output categorical decisions. Some of the most common ones are accuracy, total error (one minus accuracy), balanced accuracy, balanced total error (one minus balanced accuracy), F-score, and Matthews correlation coefficient (MCC). In this document, we review the definition of these metrics and compare them with the expected cost (EC), a metric introduced in every statistical learning course but rarely used in the machine learning literature. We show that the empirical estimate of the EC is a generalized version of both the total error and balanced total error. Further, we show its relation with F-score and MCC and argue that EC is superior to them, being more general, simpler, intuitive and well motivated. We highlight some issues with the F-score and the MCC that make them suboptimal metrics. While not explained in the current version of this manuscript, where we focus exclusively on metrics that are computed over hard decisions, the EC has the additional advantage of being a great tool to measure calibration of a system's scores and allows users to make optimal decisions given a set of posteriors for each class. We leave that discussion for a future version of this manuscript.