 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn unsupervised and customizable misspelling generator for mining noisy health-related text sources
Paper and Code

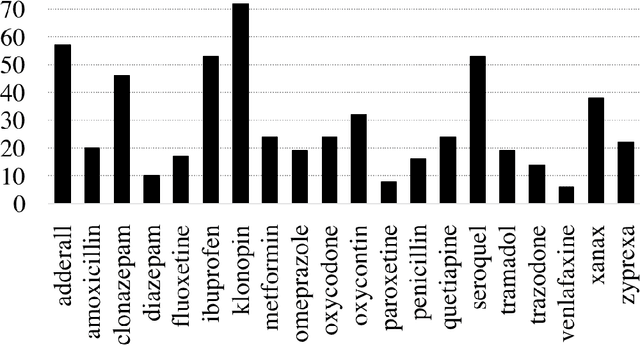
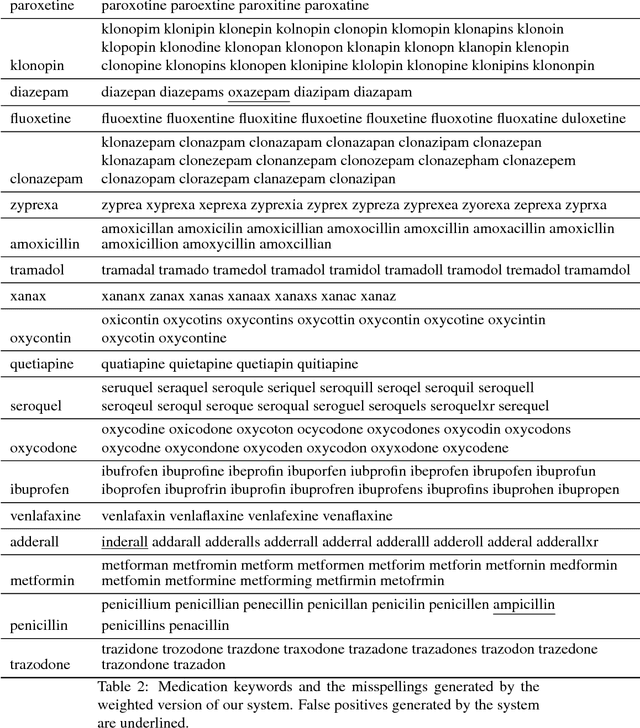

In this paper, we present a customizable datacentric system that automatically generates common misspellings for complex health-related terms. The spelling variant generator relies on a dense vector model learned from large unlabeled text, which is used to find semantically close terms to the original/seed keyword, followed by the filtering of terms that are lexically dissimilar beyond a given threshold. The process is executed recursively, converging when no new terms similar (lexically and semantically) to the seed keyword are found. Weighting of intra-word character sequence similarities allows further problem-specific customization of the system. On a dataset prepared for this study, our system outperforms the current state-of-the-art for medication name variant generation with best F1-score of 0.69 and F1/4-score of 0.78. Extrinsic evaluation of the system on a set of cancer-related terms showed an increase of over 67% in retrieval rate from Twitter posts when the generated variants are included. Our proposed spelling variant generator has several advantages over the current state-of-the-art and other types of variant generators-(i) it is capable of filtering out lexically similar but semantically dissimilar terms, (ii) the number of variants generated is low as many low-frequency and ambiguous misspellings are filtered out, and (iii) the system is fully automatic, customizable and easily executable. While the base system is fully unsupervised, we show how supervision maybe employed to adjust weights for task-specific customization. The performance and significant relative simplicity of our proposed approach makes it a much needed misspelling generation resource for health-related text mining from noisy sources. The source code for the system has been made publicly available for research purposes.